Osaa hakea useammasta tietokantataulusta tietoa JOIN-kyselyiden avulla. Osaa luoda ohjelman, joka kommunikoi tietokannanhallintajärjestelmän kanssa valmiin rajapinnan kautta. Osaa luoda ohjelman, joka hyödyntää useamman tietokantataulun sisältävää tietokantaa ja tuntee data access object (DAO) -suunnittelumallin. Osaa esittää tietoa JSON-kielellä. Osaa luoda web-sovelluksen, joka näyttää käyttäjälle tietokannasta haettua tietoa JSON-muodossa.
Tiedon hakeminen kahdesta tai useammasta taulusta
Kurssimateriaalin ensimmäisessä kahdessa osassa tutustuimme tietokannan suunnitteluun. Olemme luoneet käsiteanalyysin avulla luokkakaavion (tai käsitekaavion) ja tehneet käsitekaaviosta tietokantakaavion. Tutustuimme toisessa osassa myös SQL-kieleen, jonka tietokantakaaviosta luodaan konkreettinen tietokanta tietokannanhallintajärjestelmään. Olemme harjoitelleet myös hieman muunlaisia SQL-kyselyitä. Tutustutaan seuraavaksi tiedon hakemiseen useammasta taulusta.
Tässä luvussa oletetaan, että tietokantataulu on seuraava:
- Asiakas((pk) id:Integer, nimi:String, puhelinnumero:String, katuosoite:String, postinumero:Integer, postitoimipaikka:String)
- Ravintola((pk) id:Integer, nimi:String, puhelinnumero:String, katuosoite:String, postinumero:Integer, postitoimipaikka:String)
- Annos((pk) id:Integer, (fk) ravintola_id -> Ravintola, nimi:String, koko:String, hinta:double)
- Tilaus((pk) id:Integer, (fk) asiakas_id -> Asiakas, aika:Date, kuljetustapa:String, vastaanotettu:Boolean, toimitettu:Boolean)
- RaakaAine((pk) id:Integer, nimi:String)
- AnnosRaakaAine((fk) annos_id - > Annos, (fk) raaka_aine_id -> RaakaAine)
- TilausAnnos((fk) tilaus_id - > Tilaus, (fk) annos_id -> Annos)
Kahden tietokantataulun rivien yhdistäminen
SQL-kielen SELECT-lauseen avainsanaa FROM seuraa taulu, josta tietoa haetaan. Esimerkiksi lause SELECT * FROM Asiakas tulostaa kaikki Asiakas-taulun rivit.
Haun ei tarvitse rajoittua yhteen tauluun. Voimme määritellä haun kohteeksi useampia tauluja listaamalla ne FROM-avainsanan jälkeen pilkulla eroteltuna seuraavasti SELECT * FROM Asiakas, Tilaus. Lauseen tulos ei kuitenkaan ole tyypillisesti toivottu: jos emme kerro miten taulujen rivit yhdistetään, on lopputuloksessa kaikki ensimmäisen taulun rivit yhdistettynä kaikkiin toisen taulun riveihin -- esimerkiksi jokainen taulun Asiakas rivi yhdistettynä jokaiseen taulun Tilaus riviin.
Tällaisen kyselyn tulostaulu listaa jokaiseen asiakkaaseen kytkettynä jokaisen tilauksen, jolloin tulostaulun riveistä ei voi päätellä kenelle mikäkin tilaus kuuluu.
Taulujen yhdistäminen tapahtuu kyselyä rajaavan WHERE-ehdon avulla siten, että taulun pääavainta verrataan siihen viittaavan taulun viiteavaimeen. Esimerkiksi, jos haluamme vain asiakkaat sekä asiakkaisiin liittyvät tilaukset, hyödynnämme Asiakas-taulun pääavainta id sekä Tilaus-taulussa olevaa Asiakas-taulun pääavaimeen viittaavaa viiteavainta asiakas_id. Käytännössä tämä tapahtuu ehdolla WHERE Asiakas.id = Tilaus.asiakas_id.
Kokonaisuudessaan lause "Listaa jokaisen asiakkaan tekemät tilaukset" kirjoitetaan seuraavasti:
SELECT * FROM Asiakas, Tilaus WHERE Asiakas.id = Tilaus.asiakas_id
Tulosten nimeäminen
Useamman taulun yhdistäminen onnistuu samalla tavalla. Kaikki taulut, jotka haluamme lisätä kyselyyn, tulevat FROM-avainsanan jälkeen. Jos tauluja on useampi, on hyvä varmistaa, että kaikki taulut yhdistetään avainkenttien perusteella.
Kun yhdistämme useampia tauluja, päädymme helposti tilanteeseen, missä tuloksessa on myös useampia samannimisiä kenttiä. Esimerkiksi tilaustietokannassa taulut Asiakas, Ravintola, Annos ja RaakaAine kukin sisältää attribuutin nimi. Voimme määritellä taulun, mihin haettava kenttä liittyy, pisteoperaattorin avulla. Kyselyn SELECT nimi FROM Asiakas voi siis kirjoittaa myös muodossa SELECT Asiakas.nimi FROM Asiakas.
Voimme toisaalta myös nimetä kentän tulostusmuodon seuraavasti SELECT Asiakas.nimi AS asiakas FROM Asiakas. Edelläoleva kysely hakee Asiakas-taulusta asiakkaan nimen, mutta tulostaa nimet otsikolla 'asiakas'.
Alla oleva kysely listaa asiakkaan sekä kaikki asiakkaan tilauksissa olleet annokset. Jokainen annos tulee omalle rivilleen, joten saman nimisellä asiakkaalla voi olla listauksessa useita eri annoksia.
SELECT Asiakas.nimi AS asiakas, Annos.nimi AS annos
FROM Asiakas, Tilaus, TilausAnnos, Annos
WHERE Asiakas.id = Tilaus.asiakas_id
AND TilausAnnos.tilaus_id = Tilaus.id
AND Annos.id = TilausAnnos.annos_id;
Taulujen yhdistämisestä WHERE-kyselyllä
Jotta tietokantakysely tulostaa oleelliset rivit, on jokainen kyselyyn lisättävä taulu kytkettävä toisiinsa. Eräs hyödyllinen tapa taulujen yhdistämiseen tarvittujen kyselyjen hahmottamiseen on tietokantakaavion katsominen. Jos tavoitteena olisi esimerkiksi etsiä kaikki raaka-aineet, joita Leevi-niminen asiakas on saattanut syödä, ensimmäinen askel on etsiä polku taulusta Asiakas tauluun RaakaAine.
Aloitamme taulusta Asiakas ja etsimme polkua tauluun RaakaAine. Jotta pääsemme taulusta Asiakas tauluun RaakaAine, tulee meidän vierailla tauluissa TilausAnnos, Annos ja AnnosRaakaAine.
-
Haemme aluksi asiakkaan nimeltä Leevi.
SELECT Asiakas.nimi AS asiakas FROM Asiakas WHERE Asiakas.nimi = 'Leevi'; -
Kytketään tähän seuraavaksi kaikki Leevin tekemät tilaukset.
SELECT Asiakas.nimi AS asiakas FROM Asiakas, Tilaus WHERE Asiakas.nimi = 'Leevi' AND Tilaus.asiakas_id = Asiakas.id; -
Yhdistämme edelliseen kyselyyn taulun TilausAnnos.
SELECT Asiakas.nimi AS asiakas FROM Asiakas, Tilaus, TilausAnnos WHERE Asiakas.nimi = 'Leevi' AND Tilaus.asiakas_id = Asiakas.id AND TilausAnnos.tilaus_id = Tilaus.id; -
Yhdistämme edelliseen kyselyyn taulun Annos.
SELECT Asiakas.nimi AS asiakas FROM Asiakas, Tilaus, TilausAnnos, Annos WHERE Asiakas.nimi = 'Leevi' AND Tilaus.asiakas_id = Asiakas.id AND TilausAnnos.tilaus_id = Tilaus.id AND Annos.id = TilausAnnos.annos_id; -
Yhdistämme edelliseen kyselyyn taulun AnnosRaakaAine.
SELECT Asiakas.nimi AS asiakas FROM Asiakas, Tilaus, TilausAnnos, Annos, AnnosRaakaAine WHERE Asiakas.nimi = 'Leevi' AND Tilaus.asiakas_id = Asiakas.id AND TilausAnnos.tilaus_id = Tilaus.id AND Annos.id = TilausAnnos.annos_id AND AnnosRaakaAine.annos_id = Annos.id; -
Yhdistämme edelliseen kyselyyn taulun RaakaAine.
SELECT Asiakas.nimi AS asiakas FROM Asiakas, Tilaus, TilausAnnos, Annos, AnnosRaakaAine, RaakaAine WHERE Asiakas.nimi = 'Leevi' AND Tilaus.asiakas_id = Asiakas.id AND TilausAnnos.tilaus_id = Tilaus.id AND Annos.id = TilausAnnos.annos_id AND AnnosRaakaAine.annos_id = Annos.id AND RaakaAine.id = AnnosRaakaAine.raaka_aine_id; -
Lopulta lisäämme raaka-aineen nimien SELECT-komentoon.
SELECT Asiakas.nimi AS asiakas, RaakaAine.nimi AS raaka_aine FROM Asiakas, Tilaus, TilausAnnos, Annos, AnnosRaakaAine, RaakaAine WHERE Asiakas.nimi = 'Leevi' AND Tilaus.asiakas_id = Asiakas.id AND TilausAnnos.tilaus_id = Tilaus.id AND Annos.id = TilausAnnos.annos_id AND AnnosRaakaAine.annos_id = Annos.id AND RaakaAine.id = AnnosRaakaAine.raaka_aine_id;
Huomaa, että jokaista askelta voi ja kannattaa testata tietokannanhallintajärjestelmän tarjoamassa konsolissa.
Entä jos haluaisimme tietää vain ne henkilöt, joiden annoksessa on ollut paprikaa raaka-aineena? Tämä onnistuu edellistä kyselyä muokkaamalla näppärästi.
SELECT Asiakas.nimi AS asiakas
FROM Asiakas, Tilaus, TilausAnnos, Annos, AnnosRaakaAine, RaakaAine
WHERE RaakaAine.nimi = 'Paprika'
AND Tilaus.asiakas_id = Asiakas.id
AND TilausAnnos.tilaus_id = Tilaus.id
AND Annos.id = TilausAnnos.annos_id
AND AnnosRaakaAine.annos_id = Annos.id
AND RaakaAine.id = AnnosRaakaAine.raaka_aine_id;
Mutta! Jos henkilö on tehnyt useamman Paprikaa sisältäneen tilauksen -- tai yhteen tilaukseen liittyy useampi annos, jossa esiintyy Paprikaa -- on tulostuksessa jokaista Paprikaa sisältänyttä annosta kohden oma rivi. Tällöin henkilön nimi tulostuu kerran jokaista tulosriviä kohden.
Jos tulostukseen haluaa vain uniikit rivit, tulee kyselyyn lisätä komento DISTINCT. Kun SELECT-lauseessa on komento DISTINCT, tulostuksen rivit ovat uniikkeja.
SELECT DISTINCT Asiakas.nimi AS asiakas
FROM Asiakas, Tilaus, TilausAnnos, Annos, AnnosRaakaAine, RaakaAine
WHERE RaakaAine.nimi = 'Paprika'
AND Tilaus.asiakas_id = Asiakas.id
AND TilausAnnos.tilaus_id = Tilaus.id
AND Annos.id = TilausAnnos.annos_id
AND AnnosRaakaAine.annos_id = Annos.id
AND RaakaAine.id = AnnosRaakaAine.raaka_aine_id;
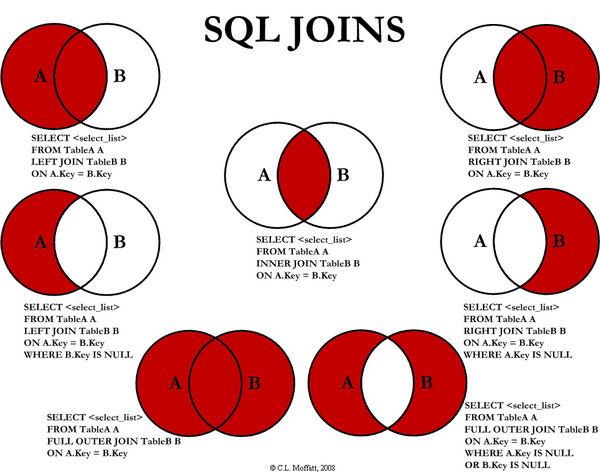
Taulujen yhdistämisestä JOIN-kyselyillä
Kyselyssä, missä taulujen rivit yhdistetään WHERE-ehdon ja avainten perusteella, valitaan näytettäväksi vain ne rivit, jotka täyttävät annetun ehdon. Entä jos haluaisimme nähdä myös ne kurssit, joita kukaan ei ole suorittanut? Tämä ei ole suoraviivaista WHERE-ehdon kautta rakennetun kyselyn avulla.
Vuonna 1992 julkaistu SQL-standardin versio toi mukanaan JOIN-kyselyt, joiden avulla edellä määritelty ongelma ratkeaa -- pienen harjoittelun kautta. Tutustutaan seuraavaksi aiemmin oppimaamme taulujen yhdistämistapaa tukeviin erityyppisiin JOIN-kyselyihin.
INNER JOIN
Edellä tutuksi tullut kysely SELECT * FROM Asiakas, Tilaus WHERE Asiakas.id = Tilaus.asiakas_id valitsee vastaukseen vain ne rivit, joiden kohdalla ehto Asiakas.id = Tilaus.asiakas_id pätee, eli missä Asiakkaan id-sarakkeen (pääavaimen) arvo on sama kuin Tilaus-taulun asiakas_id-sarakkeen (viiteavain).
Edellinen kysely voidaan kirjoittaa myös muodossa SELECT * FROM Asiakas INNER JOIN Tilaus ON Asiakas.id = Tilaus.asiakas_id.
Jos haluamme kyselyyn useampia tauluja, lisätään ne INNER JOIN -komennon avulla kyselyn jatkoksi. Esimerkiksi kaksi seuraavaa kyselyä ovat toiminnallisuudeltaan samankaltaiset.
SELECT Asiakas.nimi AS asiakas, Tilaus.aika AS tilausaika, Annos.nimi AS annos
FROM Asiakas, Tilaus, TilausAnnos, Annos
WHERE Asiakas.id = Tilaus.asiakas_id
AND TilausAnnos.tilaus_id = Tilaus.id
AND Annos.id = TilausAnnos.annos_id;
SELECT Asiakas.nimi AS asiakas, Tilaus.aika AS tilausaika, Annos.nimi AS annos
FROM Asiakas
INNER JOIN Tilaus ON Asiakas.id = Tilaus.asiakas_id
INNER JOIN TilausAnnos ON TilausAnnos.tilaus_id = Tilaus.id
INNER JOIN Annos ON Annos.id = TilausAnnos.annos_id
Kyselyn INNER JOIN avulla voimme siis tehdä kutakuinkin saman työn kuin aiemman WHERE-ehdon avulla, eli valita mukaan vain ne rivit, joiden kohdalla ehto pätee.
LEFT JOIN
Mikä tekee taulujen liitoksesta JOIN-kyselyn avulla WHERE-ehtoa monipuolisemman, on se, että JOIN-kyselyn avulla voidaan määritellä kyselyehtoa täyttämättömille riveille toiminnallisuutta. Avainsanalla LEFT JOIN voidaan määritellä kyselyn tulos sellaiseksi, että ehdon täyttävien rivien lisäksi vastaukseen sisällytetään kaikki FROM-avainsanaa seuraavan taulun rivit, joille liitosehto ei täyttynyt.
Allaoleva kysely listaa tilauksia tehneiden asiakkaiden lisäksi myös ne asiakkaat, joilla ei ole yhtäkään tilausta. Tällöin tilaukseen liittyvä vastauksen osa jää tyhjäksi.
SELECT Asiakas.nimi AS asiakas, Tilaus.aika AS tilausaika
FROM Asiakas
LEFT JOIN Tilaus ON Asiakas.id = Tilaus.asiakas_id
Liitostyypit lyhyesti
Kyselyn JOIN-tyypin voi muotoilla usealla eri tavalla:
-
INNER JOIN-- palauta vain ne rivit, joihin valintaehto kohdistuu. -
LEFT JOIN-- palauta kaikki FROM-komentoa seuraavan taulun rivit, ja liitä niihin LEFT JOIN-komentoa seuraavan taulun rivit niiltä kohdin, kuin se on ON-liitosehdossa määritellyn ehdon mukaan mahdollista -
RIGHT JOIN-- palauta kaikki RIGHT JOIN-komentoa seuraavan taulun rivit, ja liitä niihin FROM-komentoa seuraavan taulun rivit niiltä kohdin, kuin se on ON-liitosehdossa määritellyn ehdon mukaan mahdollista -
FULL JOIN-- palauta kaikki FROM-komentoa seuraavan taulun rivit sekä kaikki FULL JOIN-komentoa seuraavan taulun rivit, ja liitä ne toisiinsa niiltä kohdin, kuin se on ON-liitosehdossa määritellyn ehdon mukaan mahdollista
Valitettavasti SQLite ei tue RIGHT JOIN ja FULL JOIN -tyyppisiä kyselyitä.
C.L. Moffatt on kirjoittanut hyvän yhteenvedon erilaisista JOIN-tyypeistä. Tutustu yhteenvetoon osoitteessa http://www.codeproject.com/Articles/33052/Visual-Representation-of-SQL-Joins.
Tehtäväpohjan kansiossa db tulee tiedosto nimeltä Chinook_Sqlite.sqlite. Avaa tiedosto SQLiten avulla. Kun tietokanta on avattu oikein, komento .tables antaa seuraavanlaisen tulostuksen.
sqlite> .tables Album Employee InvoiceLine PlaylistTrack Artist Genre MediaType Track Customer Invoice Playlist
Kuten taulujen nimistä voi arvata, tietokanta kuvaa digitaalisen musiikin myyntipalvelua. Chinook on esimerkkikäyttöön tarkoitettu tietokantaprojekti, joka löytyy osoitteesta https://archive.codeplex.com/?p=chinookdatabase. Tietokannan tietokantakaavio on seuraavanlainen.
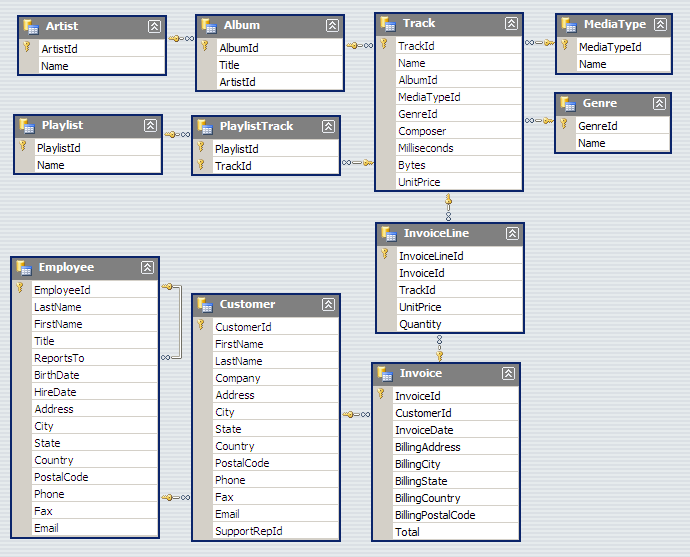
Kirjoita SQLiten avulla kyselyt, joilla saa selville seuraavat tiedot. Tehtävän palautukseen tulee antaa konkreettiset SQL-kyselyt.
-
Kysely 1: Listaa artistit, jotka soittavat Blues-musiikkia. Kyselyssä halutaan vain artistien nimet -- käytä sarakkeen nimenä joko
nametainimi -
Kysely 2: Listaa soittolistat (playlist), joilla Eric Clapton esiintyy. Kyselyssä halutaan vain soittolistojen nimet -- käytä sarakkeen nimenä joko
nametainimi -
Kysely 3: Listaa sähköpostiosoitteet niiltä asiakkailta, jotka ovat ostaneet Jazz-musiikkia. Kyselyssä halutaan vain sähköpostiosoitteet. Käytä sarakkeen nimenä nimeä
email.
Kun olet saanut kyselyt toimimaan, kopioi kyselyt tehtäväpohjassa olevan luokan Kyselyja metodeihin kysely1, kysely2 ja kysely3. Tehtävässä olevat testit ovat vain TMC-palvelimella.
Tietokannan käsittely ohjelmallisesti
Lähes jokainen ohjelmointikieli tarjoaa jonkinlaisen rajapinnan tietokantakyselyiden tekemiseen. Nämä rajapinnat suoraviivaistavat kyselyiden tekemistä tietokantoihin ja tietokannanhallintajärjestelmien käyttöönoottoa, sillä rajapintaa noudattamalla yhteydenotto tietokannantallintajärjestelmään on lähes samankaltaista käytetystä tietokannanhallintajärjestelmästä riippumatta.
Java-kielessä tähän tehtävään on Java Database Connectivity (JDBC) -rajapinta. JDBC tarjoaa tuen tietokantayhteyden luomiseen sekä kyselyiden suorittamiseen tietokantayhteyden yli. Jotta JDBCn avulla voidaan ottaa yhteys tietokantaan, tulee käytössä olla tietokannanhallintajärjestelmäkohtainen ajuri, jonka vastuulla on tietokantayhteyden luomiseen liittyvät yksityiskohdat sekä tietokannanhallintajärjestelmän sisäisten kyselytulosten muuntaminen JDBC-rajapinnan mukaiseen muotoon.
JDBC-ajurit ovat käytännössä Java-kielellä kirjoitettuja ohjelmia, joita tietokannanhallintajärjestelmän toteuttajat tarjoavat ohjelmoijien käyttöön. Kurssin toisessa osassa ajurit on lisätty valmiiksi tehtäväpohjien lib-kansioon, jonka lisäksi niiden käyttö on valmiiksi määritelty tehtäväpohjissa.
Myöhemmissä osissa tutustumme kirjastojen käyttöönottoon ja hakemiseen Maven-apuvälineen avulla.
Ohjelmallinen tietokantakysely kokonaisuudessaan
Oletetaan, että käytössämme on seuraava tietokantataulu Opiskelija:
| opiskelijanumero (integer) | nimi (varchar) | syntymävuosi (integer) | pääaine (varchar) |
|---|---|---|---|
| 9999999 | Pihla | 1997 | Tietojenkäsittelytiede |
| 9999998 | Joni | 1993 | Tietojenkäsittelytiede |
| ... |
JDBCn avulla kyselyn tekeminen tietokantatauluun tapahtuu seuraavasti -- olettaen, että käytössämme on sekä tietokanta, että tietokannan ajuri.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class Main {
public static void main(String[] args) throws Exception {
// luodaan yhteys jdbc:n yli sqlite-tietokantaan nimeltä "tietokanta.db"
Connection connection = DriverManager.getConnection("jdbc:sqlite:tietokanta.db");
// luodaan kyely "SELECT * FROM Opiskelija", jolla haetaan
// kaikki tiedot Opiskelija-taulusta
PreparedStatement statement = connection.prepareStatement("SELECT * FROM Opiskelija");
// suoritetaan kysely -- tuloksena resultSet-olio
ResultSet resultSet = statement.executeQuery();
// käydään tuloksena saadussa oliossa olevat rivit läpi -- next-komento hakee
// aina seuraavan rivin, ja palauttaa true jos rivi löytyi
while(resultSet.next()) {
// haetaan nykyiseltä riviltä opiskelijanumero int-muodossa
Integer opNro = resultSet.getInt("opiskelijanumero");
// haetaan nykyiseltä riviltä nimi String-muodossa
String nimi = resultSet.getString("nimi");
// haetaan nykyiseltä riviltä syntymävuosi int-muodossa
Integer syntVuosi = resultSet.getInt("syntymävuosi");
// haetaan nykyiseltä riviltä pääaine String-muodossa
String paaAine = resultSet.getString("pääaine");
// tulostetaan tiedot
System.out.println(opNro + "\t" + nimi + "\t" + syntVuosi + "\t" + paaAine);
}
// suljetaan lopulta yhteys tietokantaan
connection.close();
}
}
Ohjelman suoritus tuottaa (esimerkiksi) seuraavanlaisen tulostuksen:
999999 Pihla 1997 Tietojenkäsittelytiede 999998 Joni 1993 Tietojenkäsittelytiede 999997 Anna 1991 Matematiikka 999996 Krista 1990 Tietojenkäsittelytiede ...
Ohjelman rakentaminen osissa
Tässä oletetaan, että projektiin on lisätty tarvittava JDBC-ajuri.
Avaa projektiin liittyvä Source Packages ja valitse (tai tarvittaessa luo) sopiva pakkaus. Oletetaan tässä, että käytössä on pakkaus tikape. Valitse tämän jälkeen New -> Java Class, jonka jälkeen avautuu valikko, missä voit antaa luokalle nimen. Anna luokan nimeksi Main.
Avaa tiedosto tuplaklikkaamalla sitä. Muokkaa tiedostoa vielä siten, että se on seuraavan näköinen:
package tikape;
public class Main {
public static void main(String[] args) throws Exception {
}
}
Tietokantayhteyden luominen
Lisää projektiin komento import java.sql.*;, joka hakee kaikki SQL-kyselyihin liittyvät Javan kirjastot.
package tikape;
import java.sql.*;
public class Main {
public static void main(String[] args) throws Exception {
}
}
Avataan seuraavaksi tietokantayhteys tietokantatiedostoon nimeltä testi.db ja tehdään kysely "SELECT 1", jolla pyydetään tietokantaa palauttamaan luku 1 -- käytämme tätä yhteyden testaamiseksi. Jos yhteyden luominen onnistuu, tulostetaan "Hei tietokantamaailma!", muulloin "Yhteyden muodostaminen epäonnistui".
package tikape;
import java.sql.*;
public class Main {
public static void main(String[] args) throws Exception {
Connection connection = DriverManager.getConnection("jdbc:sqlite:testi.db");
PreparedStatement statement = connection.prepareStatement("SELECT 1");
ResultSet resultSet = statement.executeQuery();
if (resultSet.next()) {
System.out.println("Hei tietokantamaailma!");
} else {
System.out.println("Yhteyden muodostaminen epäonnistui.");
}
}
}
Hei tietokantamaailma!
Kun suoritamme ohjelman ensimmäistä kertaa valitsemalla Run -> Run Project, puuttuvan tietokannan paikalle luodaan tietokanta (ainakin SQLiteä käyttäessä). Projektin kansiossa on nyt tiedosto testi.db, joka on tietokantamme.
Tietokantakyselyiden tekeminen
Osoitteessa vuokraamo.db löytyy kuvitteellisen moottoripyörävuokraamon tietokanta. Lataa se edellä tehdyn projektin juureen ja kokeile kyselyn tekemistä kyseiseen tietokantaan.
Tietokannassa on tietokantataulu Pyora, jolla on sarakkeet rekisterinumero ja merkki. Jokaisen pyörän rekisterinumeron ja merkin tulostaminen tapahtuu seuraavasti -- huomaa myös, että olemme vaihtaneet käytössä olevaa tietokantaa.
Connection connection = DriverManager.getConnection("jdbc:sqlite:vuokraamo.db");
PreparedStatement stmt = connection.prepareStatement("SELECT * FROM Pyora");
ResultSet rs = stmt.executeQuery();
while (rs.next()) {
String rekisterinumero = rs.getString("rekisterinumero");
String merkki = rs.getString("merkki");
System.out.println(rekisterinumero + " " + merkki);
}
stmt.close();
rs.close();
connection.close();
Käydään ylläoleva ohjelmakoodi läpi askeleittain.
-
Luomme ensin JDBC-yhteyden tietokantaan vuokraamo.db.
Connection connection = DriverManager.getConnection("jdbc:sqlite:vuokraamo.db"); -
Kysely luodaan antamalla yhteydelle merkkijono, jossa on kysely. Yhteys palauttaa PreparedStatement-olion, jota käytetään kyselyn suorittamiseen ja tulosten pyytämiseen. Metodi executeQuery suorittaa SQL-kyselyn ja palauttaa tulokset sisältävän ResultSet-olion.
PreparedStatement statement = connection.prepareStatement("SELECT * FROM Pyora"); ResultSet resultSet = statement.executeQuery(); -
Tämän jälkeen ResultSet-oliossa olevat tulokset käydään läpi. Metodia next() kutsumalla siirrytään kyselyn palauttamissa tulosriveissä eteenpäin. Kultakin riviltä voi kysyä sarakeotsikon perusteella solun arvoa. Esimerkiksi kutsu getString("rekisterinumero") palauttaa kyseisellä rivillä olevan sarakkeen "rekisterinumero" arvon String-tyyppisenä.
while(resultSet.next()) { String rekisterinumero = rs.getString("rekisterinumero"); String merkki = rs.getString("merkki"); System.out.println(rekisterinumero + " " + merkki); } -
Kun kyselyn vastauksena saadut rivit on käyty läpi, eikä niitä enää tarvita, vapautetaan niihin liittyvät resurssit.
stmt.close(); rs.close(); -
Lopulta tietokantayhteys suljetaan.
connection.close();
Parametrien lisääminen kyselyyn
Kyselyihin halutaan usein antaa rajausehtoja. Ohjelmallisesti tämä tapahtuu lisäämällä kyselyä muodostaessa rajausehtoihin kohtia, joihin asetetaan arvot. Alla olevassa esimerkissä kyselyyn lisätään merkkijono.
PreparedStatement statement =
connection.prepareStatement("SELECT * FROM Pyora WHERE merkki = ?");
statement.setString(1, "Royal Enfield");
ResultSet resultSet = statement.executeQuery();
Kyselyiden paikat indeksoidaan kohdasta 1 alkaen. Alla olevassa esimerkissä haetaan Henkilo-taulusta henkilöitä, joiden syntymävuosi on 1952.
PreparedStatement statement =
connection.prepareStatement("SELECT * FROM Henkilo WHERE syntymavuosi = ?");
statement.setInt(1, 1952);
ResultSet resultSet = statement.executeQuery();
Ohjelma voi toimia myös siten, että rajausehdot kysytään ohjelman käyttäjältä.
Scanner lukija = new Scanner(System.in);
System.out.println("Minkä vuoden opiskelijat tulostetaan?");
int vuosi = Integer.parseInt(lukija.nextLine());
// ...
PreparedStatement statement =
connection.prepareStatement("SELECT * FROM Henkilo WHERE syntymavuosi = ?");
statement.setInt(1, vuosi);
ResultSet resultSet = statement.executeQuery();
// ...
Kun kyselyt luodaan tietokantayhteyteen liittyvän olion prepareStatement oliolla, kyselyihin merkitään kysymysmerkeillä ne kohdat, joihin käyttäjän syöttämiä arvoja voidaan lisätä. Kun ns. setterimetodilla -- esim setInt -- asetetaan parametrin arvo kyselyyn, Java tarkastaa (1) että arvo on varmasti halutun kaltainen ja (2) että arvossa ei ole esimerkiksi hipsuja, jolloin parametrina annetulla arvolla voisi vaikuttaa kyselyyn.
Päivityskyselyiden tekeminen
Myös päivityskyselyiden kuten rivien lisäämisten ja rivien poistamisten tekeminen onnistuu ohjelmallisesti. Tällöin tuloksessa ei ole erillistä ResultSet-oliota, vaan luku, joka kertoo muuttuneiden rivien määrän. Allaoleva ohjelmakoodi lisää pyöriä sisältävään tietokantaan uuden pyörän.
Connection connection = DriverManager.getConnection("jdbc:sqlite:vuokraamo.db");
PreparedStatement stmt =
connection.prepareStatement("INSERT INTO Pyora (rekisterinumero, merkki) VALUES (?, ?)");
stmt.setString(1, "RIP-34");
stmt.setString(2, "Jopo");
int changes = stmt.executeUpdate();
System.out.println("Kyselyn vaikuttamia rivejä: " + changes);
stmt.close();
connection.close();
Oliot ja tietokantataulut
Käsittelimme äskettäin tietokantakyselyiden tekemistä ohjelmallisesti. Tietokantakyselyiden tekeminen koostuu oleellisesti muutamasta osasta: (1) yhteyden muodostaminen tietokantaan, (2) kyselyn muodostaminen, (3) kyselyn suorittaminen, (4) vastausten läpikäynti, ja (5) resurssien vapauttaminen sekä yhteyden sulkeminen. Edellisessä osassa käsiteltiin Pyora-taulun sisältävää tietokantaa seuraavasti.
Connection connection = DriverManager.getConnection("jdbc:sqlite:vuokraamo.db");
PreparedStatement stmt = connection.prepareStatement("SELECT * FROM Pyora");
ResultSet rs = stmt.executeQuery();
while (rs.next()) {
String rekisterinumero = rs.getString("rekisterinumero");
String merkki = rs.getString("merkki");
System.out.println(rekisterinumero + " " + merkki);
}
stmt.close();
rs.close();
connection.close();
Ohjelmoijan näkökulmasta on paljon mielekkäämpää jos tietoa pystyy käsittelemään olioiden avulla. Oletetaan, että käytössämme on luokka Asiakas sekä tietokantataulu Asiakas. Tietokantataulu on luotu seuraavalla CREATE TABLE -lauseella.
CREATE TABLE Asiakas (
id integer PRIMARY KEY,
nimi varchar(200),
puhelinnumero varchar(20),
katuosoite varcar(50),
postinumero integer,
postitoimipaikka varchar(20)
);
Alla on taulua vastaava luokka.
public class Asiakas {
Integer id;
String nimi;
String puhelinnumero;
String katuosoite;
Integer postinumero;
String postitoimipaikka;
public Asiakas(Integer id, String nimi, String puhelinnumero, String
katuosoite, Integer postinumero, String postitoimipaikka) {
this.id = id;
this.nimi = nimi;
this.puhelinnumero = puhelinnumero;
this.katuosoite = katuosoite;
this.postinumero = postinumero;
this.postitoimipaikka = postitoimipaikka;
}
// muita metodeja ym
}
Hakiessamme tietoa tietokantataulusta Asiakas voimme muuntaa kyselyn tulokset Asiakas-olioiksi.
Connection connection = DriverManager.getConnection("jdbc:sqlite:tietokanta.db");
PreparedStatement stmt = connection.prepareStatement("SELECT * FROM Asiakas");
ResultSet rs = stmt.executeQuery();
List<Asiakas> asiakkaat = new ArrayList<>();
while (rs.next()) {
Asiakas a = new Asiakas(rs.getInt("id"), rs.getString("nimi"),
rs.getString("puhelinnumero"), rs.getString("katuosoite"),
rs.getInt("postinumero"), rs.getString("postitoimipaikka"));
asiakkaat.add(a);
}
stmt.close();
rs.close();
connection.close();
// nyt asiakkaat listassa
Myös uuden Asiakas-olion tallentaminen tietokantatauluun onnistuu.
Connection connection = DriverManager.getConnection("jdbc:sqlite:tietokanta.db");
PreparedStatement stmt = connection.prepareStatement("INSERT INTO Asiakas"
+ " (nimi, puhelinnumero, katuosoite, postinumero, postitoimipaikka)"
+ " VALUES (?, ?, ?, ?, ?)");
stmt.setString(1, asiakas.getNimi());
stmt.setString(2, asiakas.getPuhelinnumero());
stmt.setString(3, asiakas.getKatuosoite());
stmt.setInt(4, asiakas.getPostinumero());
stmt.setString(5, asiakas.getPostitoimipaikka());
stmt.executeUpdate();
stmt.close();
// voimme halutessamme tehdä myös toisen kyselyn, jonka avulla saadaan selville
// juuri tallennetun olion tunnus -- alla oletetaan, että asiakkaan voi
// yksilöidä nimen ja puhelinnumeron perusteella
stmt = connection.prepareStatement("SELECT * FROM Asiakas"
+ " WHERE nimi = ? AND puhelinnumero = ?");
stmt.setString(1, asiakas.getNimi());
stmt.setString(2, asiakas.getPuhelinnumero());
ResultSet rs = stmt.executeQuery();
rs.next(); // vain 1 tulos
Asiakas a = new Asiakas(rs.getInt("id"), rs.getString("nimi"),
rs.getString("puhelinnumero"), rs.getString("katuosoite"),
rs.getInt("postinumero"), rs.getString("postitoimipaikka"));
stmt.close();
rs.close();
connection.close();
DAO-suunnittelumalli
Tähän astisissa simerkeissä tietokantakyselytoiminnallisuus ja muu toiminnallisuudesta on ollut samassa luokassa, mikä johtaa helposti sekavaan koodiin.
Tietokantasovelluksia toteuttaessa on hyvin tyypillistä abstrahoida konkreettinen tiedon hakemis- ja tallennustoiminnallisuus siten, että ohjelmoijan ei tarvitse nähdä sitä jatkuvasti.
Wikipedia: In computer software, a data access object (DAO) is an object that provides an abstract interface to some type of database or other persistence mechanism. By mapping application calls to the persistence layer, DAO provide some specific data operations without exposing details of the database. This isolation supports the Single responsibility principle. It separates what data accesses the application needs, in terms of domain-specific objects and data types (the public interface of the DAO), from how these needs can be satisfied with a specific DBMS, database schema, etc. (the implementation of the DAO).
Although this design pattern is equally applicable to the following: (1- most programming languages; 2- most types of software with persistence needs; and 3- most types of databases) it is traditionally associated with Java EE applications and with relational databases (accessed via the JDBC API because of its origin in Sun Microsystems' best practice guidelines "Core J2EE Patterns" for that platform).
Hahmotellaan hakemiseen ja poistamiseen liittyvää rajapintaa, joka tarjoaa metodit findOne, findAll, saveOrUpdate ja delete, eli toiminnallisuudet hakemiseen, tallentamiseen ja poistamiseen. Tehdään rajapinnasta geneerinen, eli toteuttava luokka määrittelee palautettavien olioiden tyypin sekä avaimen.
import java.sql.*;
import java.util.*;
public interface Dao<T, K> {
T findOne(K key) throws SQLException;
List<T> findAll() throws SQLException;
T saveOrUpdate(T object) throws SQLException;
void delete(K key) throws SQLException;
}
Metodi findOne hakee tietyllä avaimella haettavan olion, jonka tyyppi voi olla mikä tahansa, ja metodi saveOrUpdate joko tallentaa olion tai päivittää tietokannassa olevaa oliota riippuen siitä, onko olion id-kentässä arvoa. Alustava hahmotelma konkreettisesta asiakkaiden käsittelyyn tarkoitetusta AsiakasDao-luokasta on seuraavanlainen.
import java.util.*;
import java.sql.*;
public class AsiakasDao implements Dao<Asiakas, Integer> {
@Override
public Asiakas findOne(Integer key) throws SQLException {
// ei toteutettu
return null;
}
@Override
public List<Asiakas> findAll() throws SQLException {
// ei toteutettu
return null;
}
@Override
public Asiakas saveOrUpdate(Asiakas object) throws SQLException {
// ei toteutettu
return null;
}
@Override
public void delete(Integer key) throws SQLException {
// ei toteutettu
}
}
Käytännössä tyyppiparametrit annetaan rajapinnan toteuttamisesta kertovan avainsanan implements-yhteyteen. Ylläolevassa esimerkissä haettavan olion tyyppi on Asiakas, ja sen pääavain on tyyppiä Integer.
Luodaan tietokanta-abstraktio, jolta voidaan pyytää tietokantayhteyttä tarvittaessa.
import java.sql.*;
public class Database {
private String databaseAddress;
public Database(String databaseAddress) throws ClassNotFoundException {
this.databaseAddress = databaseAddress;
}
public Connection getConnection() throws SQLException {
return DriverManager.getConnection(databaseAddress);
}
}
Jatketaan luokan AsiakasDao toteuttamista. Lisätään luokkaan tietokannan käyttö tietokanta-abstraktion avulla sekä asiakkaan poistaminen avaimen perusteella
import java.util.*;
import java.sql.*;
public class AsiakasDao implements Dao<Asiakas, Integer> {
private Database database;
public AsiakasDao(Database database) {
this.database = database;
}
@Override
public Asiakas findOne(Integer key) throws SQLException {
// ei toteutettu
return null;
}
@Override
public List<Asiakas> findAll() throws SQLException {
// ei toteutettu
return null;
}
@Override
public Asiakas saveOrUpdate(Asiakas object) throws SQLException {
// ei toteutettu
return null;
}
@Override
public void delete(Integer key) throws SQLException {
Connection conn = database.getConnection();
PreparedStatement stmt = conn.prepareStatement("DELETE FROM Asiakas WHERE id = ?");
stmt.setInt(1, key);
stmt.executeUpdate();
stmt.close();
conn.close();
}
}
Vastaavasti yksittäisen asiakkaan noutaminen onnistuisi findOne-metodilla.
import java.util.*;
import java.sql.*;
public class AsiakasDao implements Dao<Asiakas, Integer> {
private Database database;
public AsiakasDao(Database database) {
this.database = database;
}
@Override
public Asiakas findOne(Integer key) throws SQLException {
Connection conn = database.getConnection();
PreparedStatement stmt = conn.prepareStatement("SELECT * FROM Asiakas WHERE id = ?");
stmt.setInt(1, key);
ResultSet rs = stmt.executeQuery();
boolean hasOne = rs.next();
if (!hasOne) {
return null;
}
Asiakas a = new Asiakas(rs.getInt("id"), rs.getString("nimi"),
rs.getString("puhelinnumero"), rs.getString("katuosoite"),
rs.getInt("postinumero"), rs.getString("postitoimipaikka"));
stmt.close();
rs.close();
conn.close();
return a;
}
@Override
public List<Asiakas> findAll() throws SQLException {
// ei toteutettu
return null;
}
@Override
public Asiakas saveOrUpdate(Asiakas object) throws SQLException {
// ei toteutettu
return null;
}
@Override
public void delete(Integer key) throws SQLException {
Collection conn = database.getConnection();
PreparedStatement stmt = conn.prepareStatement("DELETE FROM Asiakas WHERE id = ?");
stmt.setInt(1, key);
stmt.executeUpdate();
stmt.close();
conn.close();
}
}
Ja niin edelleen. Nyt asiakkaiden muokkaaminen on DAO-rajapintaa käyttävän ohjelman näkökulmasta hieman helpompaa.
Database database = new Database("jdbc:sqlite:kanta.db");
AsiakasDao asiakkaat = new AsiakasDao(database);
Scanner lukija = new Scanner(System.in);
System.out.println("Millä tunnuksella asiakasta haetaan?");
int tunnus = Integer.parseInt(lukija.nextLine());
Asiakas a = asiakkaat.findOne(tunnus);
System.out.println("Asiakas: " + a);
Viitteet olioiden välillä
Edellisessä esimerkissä käsittelimme yksittäistä oliota, josta ei ole viitteitä muihin käsitteisiin. Hahmotellaan seuraavaksi Tilaus-käsitteen käsittelyä ohjelmallisesti. Luodaan ensin Tilausta kuvaava luokka ja toteutetaan tämän jälkeen tilausten tallennuksesta ja käsittelystä vastaava DAO-luokka.
public class Tilaus {
Integer id;
Asiakas asiakas;
Date aika;
String kuljetustapa;
Boolean vastaanotettu;
Boolean toimitettu;
// konstruktorit sekä getterit ja setterit
}
Toteutetaan tilausten käsittelyyn tarkoitettu DAO-luokka siten, että se saa konstruktorissaan sekä viitteen tietokanta-olioon että viitteen asiakkaiden hakemiseen tarkoitettuun Dao-rajapintaan.
import java.util.*;
import java.sql.*;
public class TilausDao implements Dao<Tilaus, Integer> {
private Database database;
private Dao<Asiakas, Integer> asiakasDao;
public TilausDao(Database database, Dao<Asiakas, Integer> asiakasDao) {
this.database = database;
this.asiakasDao = asiakasDao;
}
@Override
public Tilaus findOne(Integer key) throws SQLException {
Connection connection = database.getConnection();
PreparedStatement stmt = connection.prepareStatement("SELECT * FROM Tilaus WHERE id = ?");
stmt.setObject(1, key);
ResultSet rs = stmt.executeQuery();
boolean hasOne = rs.next();
if (!hasOne) {
return null;
}
Asiakas asiakas = asiakasDao.findOne(rs.getInt("asiakas_id"));
Tilaus t = new Tilaus(key, asiakas,
rs.getDate("aika"), rs.getString("kuljetustapa"),
rs.getBoolean("vastaanotettu"), rs.getBoolean("toimitettu"));
rs.close();
stmt.close();
connection.close();
return t;
}
@Override
public List<Tilaus> findAll() throws SQLException {
// ei toteutettu
return null;
}
@Override
public Tilaus saveOrUpdate(Tilaus object) throws SQLException {
// ei toteutettu
return null;
}
@Override
public void delete(Integer key) throws SQLException {
// ei toteutettu
}
}
Nyt yksittäisen tilauksen hakemisen yhteydessä palautetaan sekä tilaus, että siihen liittyvä asiakas. Rajapintaa käyttävän toteutuksen näkökulmasta tietokannan käyttäminen toimii seuraavasti:
Database database = new Database("jdbc:sqlite:kanta.db");
AsiakasDao asiakkaat = new AsiakasDao(database);
TilausDao tilaukset = new TilausDao(database, asiakkaat);
Tilaus t = tilaukset.findOne(4);
System.out.println("Tilauksen teki: " + t.getAsiakas().getNimi());
Kun jatkamme edellistä esimerkkiä, pitäisikö annosta haettaessa hakea aina siihen liittyvä ravintola? Entä pitääkö tilausta haettaessa oikeasti hakea myös tilaukseen liittyvä asiakas?
Hyvä kysymys. Kun tietokantataulujen välisten yhteyksien perusteella tehdään uusia kyselyitä tietokantaan, olemassa on oleellisesti kaksi vaihtoehtoa sekä niiden seuraukset: (1) haetaan liikaa tietoa, jolloin hakemisoperaatioon menee turhaan aikaa, tai (2) haetaan liian vähän tietoa, jolloin tieto tulee hakea myöhemmin.
Yksi tapa ratkaista ongelma on toimia siten, että tietoa haetaan vain silloin kun sitä tarvitaan. Tällöin esimerkiksi vasta Tilaus-olioon mahdollisesti liittyvää getAsiakas-metodia kutsuttaessa asiakkaaseen liittyvät tiedot haettaisiin tietokannasta -- getAsiakas-metodi tekisi siis tietokantahaun. Tämäkään ei kuitenkaan ratkaise tilannetta, sillä jos tavoitteenamme olisi vaikkapa tulostaa kaikki tilaukset ja niihin liittyvät asiakkaat -- edellisellä lähestymistavalla kaksi tietokantakyselyä -- saattaisi toteutus lopulta tehdä jokaisen tilauksen ja asiakkaan kohdalla oman erillisen tietokantahaun.
Tähän ei ole suoraviivaista ratkaisua. Tyypillisesti Dao-rajapinnan määrittelemille metodeille kerrotaan, tuleeko haettaviin olioihin liittyvät viitteet hakea erikseen.
Tehtäväpohjassa on mukana edellisessä esimerkeissä luodut AsiakasDao ja TilausDao sekä niihin liittyvät luokat. Toteuta luokkien AsiakasDao ja TilausDao findAll-metodit siten, että ne hakevat kaikki käsiteltävään tauluun liittyvät rivit. AsiakasDaon metodin findAll tulee siis hakea ja palauttaa kaikki asiakkaat, ja TilausDaon metodin findAll tulee hakea ja palauttaa kaikki tilaukset.
Toteuta luokan TilausDao metodi findAll siten, että jokaiseen noudettuun tilaukseen liittyy myös tilauksen tehnyt asiakas. Tehtäväpohjassa olevassa kansiossa db on mukana tiedosto tilauskanta.db, johon tietokannan taulut ovat luotuna. Lisää tietokantaan testidataa tarvittaessa.
Tehtäväpohjassa olevista testeistä saattaa olla hyötyä toteutusta tehdessä..
Ensimmäinen web-sovellus
Selaimen -- ja nykyään kännykän -- kautta käytettävät sovellukset ovat lähes poikkeuksetta syrjäyttäneet perinteiset työpöytäsovellukset. Tietokannan käyttö sovelluksen osana ei kuitenkaan ole muuttunut. Työpöytäsovellusten aikana työpöytäsovellus käytti joko paikallisella koneella olevaa tietokannanhallintajärjestelmää, tai otti etäyhteyden toisella koneella käynnissä olevaan tietokannanhallintajärjestelmään. Selaimessa toimivia sovelluksia käytettäessä tietokannanhallintajärjestelmä toimii palvelinohjelmiston -- eli sovelluksen, johon selain ottaa yhteyttä -- kanssa samalla koneella, tai erillisellä koneella, johon palvelinohjelmisto ottaa yhteyden tarvittaessa.
Tutustumme seuraavaksi lyhyesti tietokantaa käyttävän palvelinohjelmiston toimintaan ja toteutukseen.
Projektinhallintatyökalu Maven
Jotta Javalla ja NetBeansilla tehtävään projektiin saa tietokannan käyttöön, tulee ohjelmoijan noutaa tietokanta-ajuri. Ajurien noutaminen kannattaa hoitaa ns. riippuvuuksia hallinnoivan projektinhallintatyökalun, kuten Mavenin, avulla.
Maven-projektin luominen NetBeansissa
Uuden Mavenia käyttävän projektin luominen NetBeansissa tapahtuu valitsemalla File -> New Project -> Kategoriaksi Maven ja projektiksi Java Application. Tämän jälkeen valitaan Next, ja täytetään projektin tiedot. Alla on esimerkki projektin tiedoista, projektin sijainti (Project location) on konekohtainen.
Tämän jälkeen painetaan Finish, ja projekti ilmestyy NetBeansin vasemmassa laidassa olevalle listalle. Etsi nyt projektin Project Files sisältä pom.xml-tiedosto. Koska käytössämme on Java 8, varmistetaan että sekä maven.compiler.source että maven.compiler.target arvot ovat 1.8.
<?xml version="1.0" encoding="UTF-8"?>
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>tikape</groupId>
<artifactId>tikape</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
</project>
Kirjastojen lisääminen projekteihin Mavenin avulla
Kirjastot kuten tietokanta-ajurit ja web-sovelluksen luomiseen tarvittavat apukirjastot ladataan Maven-työkalun avulla. Mavenin termein kirjastoja kutsutaan riippuvuuksiksi (dependency). Lisätään esimerkiksi SQLite-ajuri sekä logituskirjasto SLF4J projektin käyttöön.
<?xml version="1.0" encoding="UTF-8"?>
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>tikape</groupId>
<artifactId>tikape</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.xerial</groupId>
<artifactId>sqlite-jdbc</artifactId>
<version>3.21.0.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.25</version>
</dependency>
</dependencies>
</project>
Kun NetBeans-projektista valitsee oikealla hiirennapilla Dependencies ja klikkaa Download Declared Dependencies, latautuu JDBC-ajuri projektin käyttöön.
Tietokantaa käyttävä ohjelma
Kokeillaan seuraavaksi että sovellukset toimivat myös Mavenilla. Avaa projektiin liittyvä Source Packages, ja klikkaa tikape-pakkausta oikealle hiirennapilla. Valitse tämän jälkeen New -> Java Class, jonka jälkeen avautuu valikko, missä voit antaa luokalle nimen. Anna luokan nimeksi Main.
Avaa tiedosto tuplaklikkaamalla sitä. Muokkaa tiedostoa vielä siten, että se on seuraavan näköinen:
package tikape;
public class Main {
public static void main(String[] args) throws Exception {
}
}
Lisää projektiin import-komento import java.sql.*;, joka hakee kaikki SQL-kyselyihin liittyvät Javan kirjastot.
package tikape;
import java.sql.*;
public class Main {
public static void main(String[] args) throws Exception {
}
}
Avataan seuraavaksi tietokantayhteys tietokantaan testi.db, ja tehdään siellä kysely "SELECT 1", jolla pyydetään tietokantaa palauttamaan luku 1 -- käytämme tätä yhteyden testaamiseksi. Jos yhteyden luominen onnistuu, tulostetaan "Hei tietokantamaailma!", muulloin "Yhteyden muodostaminen epäonnistui".
package tikape;
import java.sql.*;
public class Main {
public static void main(String[] args) throws Exception {
Connection connection = DriverManager.getConnection("jdbc:sqlite:testi.db");
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery("SELECT 1");
if (resultSet.next()) {
System.out.println("Hei tietokantamaailma!");
} else {
System.out.println("Yhteyden muodostaminen epäonnistui.");
}
}
}
Hei tietokantamaailma!
Tietokantaa käyttävien web-sovellusten rakentaminen
Selain kommunikoi palvelimen kanssa tekemällä pyyntöjä joihin palvelin vastaa. Selain tekee pyynnön esimerkiksi kun käyttäjä kirjoittaa osoitekenttään sivun osoitteen -- esimerkiksi https://materiaalit.github.io/tikape-s17/ -- ja painaa enter. Tällöin tehdään hakupyyntö (GET) osoitteessa materiaalit.github.io olevalle palvelimelle. Palvelin vastaanottaa pyynnön, käsittelee sen -- esimerkiksi hakee haluttavan dokumentin tiedostojärjestelmästä -- ja luo käyttäjälle näytettävän sivun. Sivu palautetaan vastauksena pyynnölle tekstimuodossa. Selain päättelee vastauksen sisällön perusteella miten sivu tulee näyttää käyttäjälle ja näyttää sivun käyttäjälle.
Sivun näyttämisen yhteydessä selain hakee myös sisältöä, joihin sivu viittaa. Esimerkiksi jokainen tällä sivulla oleva kuva haetaan erikseen, aivan kuten erilaiset dynaamista toiminnallisuutta lisäävät Javascript -tiedostot sekä sivun ulkoasun tyylittelyyn liittyvät tyylitiedostot.
Käyttäjän näkökulmasta selain tekee käytännössä kahdenlaisia pyyntöjä. Hakupyynnöt (GET) liittyvät tietyssä osoitteessa olevan resurssin hakemiseen, kun taas lähestyspyynnöt (POST) liittyvät tiedon lähettämiseen tiettyyn osoitteeseen.
Tutustutaan tähän käytännössä Javalla toteutetun Spark-nimisen web-sovelluskehyksen avulla.
Spark ja ensimmäinen web-sovellus
Spark-sovelluskehyksen käyttöönotto toimii kuten aliluvussa 4.1. "Maven-projektin luominen NetBeansissa". Toisin kuin oppaassa, Maven-projektin riippuvuudeksi halutaan lisätä useampia kirjastoja, jotka yhdessä tarjoavat sekä tietokanta- että palvelintoiminnallisuuden. Tiedosto pom.xml näyttää lopuksi esimerkiksi seuraavalta:
<?xml version="1.0" encoding="UTF-8"?>
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>tikape</groupId>
<artifactId>tikape-web-sample</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.xerial</groupId>
<artifactId>sqlite-jdbc</artifactId>
<version>3.21.0.1</version>
</dependency>
<dependency>
<groupId>com.sparkjava</groupId>
<artifactId>spark-core</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.25</version>
</dependency>
</dependencies>
</project>
Nyt voimme luoda uuden pääohjelmaluokan. Lisätään Main.java-tiedostoon rivi import spark.Spark;, jolloin käyttöömme tulee oleellisimmat Sparkin tarjoamat toiminnallisuudet. Kutsutaan tämän jälkeen Sparkin get-metodia, ja määritellään sen avulla osoite, jota palvelinohjelmistomme tulee kuuntelemaan, sekä teksti, joka palautetaan, kun selaimella tehdään pyyntö annettuun osoitteeseen.
package tikape;
import spark.Spark;
public class Main {
public static void main(String[] args) {
Spark.get("/hei", (req, res) -> {
return "Hei maailma!";
});
}
}
Yllä olevassa esimerkissä palvelimelle määritellään osoite /hei. Jos selaimella tehdään osoitteeseen pyyntö, pyyntöön vastataan tekstillä Hei maailma!.
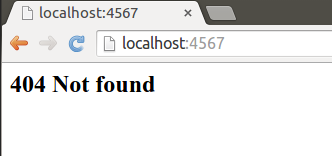
Kun ylläolevan sovelluksen käynnistää, Spark käynnistää web-palvelimen osoitteeseen http://localhost:4567, eli paikallisen koneen porttiin 4567. Palvelin on tämän jälkeen käynnissä, ja odottaa siihen tehtäviä pyyntöjä. Kun haemme web-selaimella sivua osoitteesta http://localhost:4567, palauttaa palvelin selaimelle tekstimuotoista tietoa, ja selain näyttää käyttäjälle seuraavanlaisen sivun:
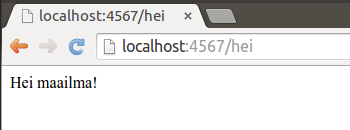
Kun teemme pyynnön osoitteeseen http://localhost:4567/hei, eli palvelinohjelmiston osoitteeseen /hei, saammekin vastaukseksi ohjelmakoodissa määrittelemämme Hei maailma!-tekstin.
Palvelimen sammuttaminen tapahtuu NetBeansissa punaista neliötä klikkaamalla. Joissakin käyttöjärjestelmissä (mac) tämä ei kuitenkaan toimi oikein, jolloin palvelin tulee sammuttaa komentoriviltä.
Saat portissa 4567 käynnissä olevan prosessin tunnuksen tietoon terminaalissa komennolla lsof -i :4567. Etsi komennon palauttamasta tulosteesta prosessin tunnus, jonka jälkeen voit sammuttaa prosessin komennolla kill -9 prosessin-tunnus.
Esimerkiksi:
> lsof -i :4567 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME java 9916 kayttaja 51u IPv6 0x65802ef6be5c6f29 0t0 TCP *:tram (LISTEN) >
Yllä prosessin tunnus (PID) on 9916. Tämän jälkeen prosessi sammutetaan komennolla kill -9 9916.
> lsof -i :4567 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME java 9916 kayttaja 51u IPv6 0x65802ef6be5c6f29 0t0 TCP *:tram (LISTEN) > kill -9 9916
Tietokannasta haetun tiedon palauttaminen Spark-sovelluksessa
Luodaan seuraavaksi sovellus, jonka avulla tietokantaan voi lisätä tietoa ja joka palauttaa tietoa tietokannasta. Tietoa lähetetään selaimen tai muun asiakasohjelmiston tekemällä POST-tyyppisellä pyynnöllä, ja tietoa haetaan GET-tyyppisellä pyynnöllä. Näitä varten Sparkissa on metodit post ja get.
Oletamme, että tietokanta käsittelee tehtäviä. Tehtävää kuvaava luokka ja tietokanta on seuraavanlainen.
public class Todo {
Integer id; // pääavain
String tehtava; // tehtävän kuvaus
Boolean tehty; // tieto onko tehtävä tehty
}
CREATE TABLE Todo (
id integer PRIMARY KEY,
tehtava varchar(255),
tehty boolean
);
Käytämme tässä esimerkissä tiedon esitysmuotona JSON-formaattia. JSON (Javascript Object Notation) sisältää oleellisesti kaksi tietirakennetta: avain-arvo -parit sekä listat. JSON-olio aloitetaan aaltosuluilla, jota seuraa muuttujat ja niiden arvot. Alla Todo-olio kuvattuna JSON-muodossa.
{
"id": 3,
"tehtava": "Lue JSON-opas",
"tehty": false
}
Kun käytössämme on aiemmin tutuksi tullut Dao-rajapinta, on Todo-olioiden käsittely suoraviivaista.
Database db = new Database("jdbc:sqlite:todot.db");
TodoDao dao = new TodoDao<Todo, Integer>();
Todo todo = new Todo();
todo.setTehtava("Lue JSON-opas");
dao.saveOrUpdate(todo);
for(Todo t: dao.findAll()) {
System.out.println(t.getId() + "\t" + t.getTehtava());
}
1 Lue JSON-opas false
Olioiden kääntäminen JSON-muotoiseksi tiedoksi onnistuu helposti Googlen Gson-kirjaston avulla.
Gson gson = new Gson();
Todo t = new Todo();
t.setId(1);
t.setTehtava("Tutustu Gson-kirjastoon");
t.setTehty(false);
System.out.println(gson.toJson(gson));
{"id": 1, "tehtava": "Tutustu Gson-kirjastoon", "tehty": false}
Yhdistämällä Sparkin, tietokannan, daon sekä Gson-kirjaston, saamme käyttöömme kevyen web-palvelun, joka tarjoaa JSON-muotoista dataa.
package tikape;
import com.google.gson.Gson;
import spark.Spark;
public class Main {
public static void main(String[] args) throws Exception {
Database db = new Database("jdbc:sqlite:todot.db");
TodoDao dao = new TodoDao(db);
Gson gson = new Gson();
Spark.get("*", (req, res) -> {
return gson.toJson(dao.findAll());
});
Spark.post("*", (req, res) -> {
Todo todo = gson.fromJson(req.body(), Todo.class);
todo = dao.saveOrUpdate(todo);
return gson.toJson(todo);
});
}
}
Selvitä Sparkin dokumentaatiosta tarkemmin mitä yllä oleva sovellus todellisuudessa tekee.
Toteuta edellistä esimerkkiä noudattaen sovellus, joka mahdollistaa palvelimella sijaitsevien Todo-olioiden lisäämisen ja hakemisen. Luo sovelluksen tietokanta nimellä todot.db tehtäväpohjan kansioon db. Käytä tietokannan rakenteena seuraavaa:
CREATE TABLE Todo (
id integer PRIMARY KEY,
tehtava varchar(255),
tehty boolean
);
Hyödynnä tehtäväpohjan luokkaa Todo tietokannasta noudettavien tehtävien noutamisessa ja tietokantaan tallentamisessa. Tarvitset sovellukseen myös mahdollisesti erillisen TodoDao-luokan..
JSON-muotoisen tiedon lähettämistä palvelimelle voi kokeilla komentoriviltä cURL-työvälineen avulla. Tämä löytyy tietojenkäsittelytieteen laitoksen koneilta, mutta sen voi myös ladata osoitteesta https://curl.haxx.se/download.html.
curl -d '{"tehtava":"test", "tehty":"true"}' -H "Content-Type: application/json" -X POST http://localhost:4567