Osaa tehdä yhteenvetokyselyitä SQL-kielellä. Osaa selvittää miten tietokannanhallintajärjestelmä hakee annetun SQL-kyselyn tuloksen. Tietää mitä indeksit ovat ja tietää milloin tietokantatauluun tulee määritellä indeksejä. Tuntee käsitteet tietokannan eheys ja tietokantatransaktio, ja tietää tilanteita milloin transaktioita kannattaa käyttää. Tietää tietokannanhallintajärjestelmältä vaadittuja ominaisuuksia, joita tarvitaan tietokantatransaktioiden toimintaan. Tuntee CAP-teoreeman ja tietää GDPR-lainsäädännön olemassaolon sekä ainakin muutamia siihen liittyviä säännöksiä.
Yhteenvetokyselyt SQL-kielellä
Harjoittelemamme SQL-kyselyt ovat tähän mennessä tuottaneet listauksia tietokantataulujen sisällöistä. Listauksia tuottavat kyselyt ovat erittäin hyödyllisiä, kun halutaan vastata esimerkiksi kysymyksiin kuten "Listaa kaikki opiskelijat, jotka ovat osallistuneet kurssille tietokantojen perusteet" tai "Listaa kaikki kurssit, joille annettu opiskelija on ilmoittautunut". Kysymykset kuten "Kuinka moni opiskelija on osallistunut kurssille tietokantojen perusteet" ovat kuitenkin vaatineet manuaalista työtä, sillä kyselyn tulosrivit on pitänyt laskea käsin tai jonkun toisen ohjelman avulla.
SQL-kieli tarjoaa välineitä yhteenvetokyselyiden tekemiseen. Tällaisia kyselyitä ovat esimerkiksi juurikin yllä mainittu "kuinka moni" -- eli tulosrivien määrä -- sekä esimerkiksi erilaiset summa- ja keskiarvokyselyt. Käytännössä yhteenvetokyselyt tehdään SQL-kielen tarjoamien funktioiden avulla, jotka muuntavat tulosrivit toiseen muotoon. Alla on listattuna muutamia tyypillisimpiä funktioita, joita tietokantakyselyissä käytetään.
| Tavoite | Funktio | Esimerkki |
|---|---|---|
| Rivien lukumäärän selvittäminen |
COUNT
|
|
| Numeerisen sarakkeen keskiarvon laskeminen |
AVG
|
|
| Numeerisen sarakkeen summan laskeminen |
SUM
|
|
| Numeerisen sarakkeen minimiarvon selvittäminen |
MIN
|
|
| Numeerisen sarakkeen maksimiarvon selvittäminen |
MAX
|
|
Tarkastellaan näitä kyselyitä hieman tarkemmin. Oletetaan, että käytössämme on seuraava lentomatkoja kuvaava tietokantataulu.
| Lentomatka(yhtio, lahtopaikka, maaranpaa, pituus) | |||
|---|---|---|---|
| Lentoyhtiö | Lähtöpaikka | Määränpää | Lennon pituus (minuuttia) |
| Air Berlin | Helsinki | Berliini | 205 |
| Finnair | Helsinki | Oulu | 70 |
| Finnair | Helsinki | Berliini | 200 |
| Finnair | Helsinki | Tukholma | 50 |
| Finnair | Helsinki | Mallorca | 230 |
| Norwegian | Helsinki | Mallorca | 240 |
Yhteenvetokyselyiden avulla saamme selville erilaisia tilastoja. Alla muutamia esimerkkejä:
-
Kuinka monta matkaa tietokantataulussa Lentomatka on yhteensä?
SELECT COUNT(*) FROM Lentomatka -
Kuinka monta lentoyhtiötä on tietokantataulussa lentomatka? (Huomaa avainsanan DISTINCT käyttö)
SELECT COUNT(DISTINCT yhtio) FROM Lentomatka -
Kuinka monta lentoa taulussa on Helsingistä Mallorcalle?
SELECT COUNT(*) FROM Lentomatka WHERE lahtopaikka = 'Helsinki' AND maaranpaa = 'Mallorca' -
Mikä on keskimääräinen Finnairin lennon pituus?
SELECT AVG(pituus) FROM Lentomatka WHERE yhtio = 'Finnair' -
Mikä on lyhin matkan kesto Helsingistä Berliiniin?
SELECT MIN(pituus) FROM Lentomatka WHERE lahtopaikka = 'Helsinki' AND maaranpaa = 'Berliini'
Yllä olevat esimerkit tuottavat tulokseksi aina yhden luvun. Entä jos haluaisimme saada selville yhtiökohtaisia tietoja kuten vaikkapa jokaisen yhtiön lyhimmän lennon? Tarkastellaan tätä seuraavaksi.
Tehtäväpohjan kansiossa db tulee tiedosto nimeltä Chinook_Sqlite.sqlite. Käytimme samaa tiedostoa myös yhdessä osan 3 tehtävistä. Tietokannassa on seuraavat taulut:
sqlite> .tables Album Employee InvoiceLine PlaylistTrack Artist Genre MediaType Track Customer Invoice Playlist
Tietokanta kuvaa digitaalisen musiikin myyntipalvelua. Tietokannan relaatiokaavio löytyy osoitteesta https://github.com/lerocha/chinook-database/wiki/Chinook-Schema. Kirjoita SQLiten avulla kyselyt, joilla saa selville seuraavat tiedot.
- Kysely 1: Kuinka monta albumia (Album) tietokannassa on yhteensä?
- Kysely 2: Minkä on kaikkien tietokannassa olevien laskujen (Invoice) hinnan (total) keskiarvo?
- Kysely 3: Kuinka monta 'Blues', 'Jazz' tai 'Metal'-genren kappaletta tietokannassa on yhteensä?
Kun olet saanut kyselyt toimimaan, kopioi ne tehtäväpohjassa olevan luokan Kyselyja metodeihin kysely1, kysely2 ja kysely3. Metodeihin tulee siis kopioida SQL-kieliset kyselyt, joilla em. kysymyksiin saa vastaukset, ei kyselyiden vastauksia.
Tulosten ryhmittely
Tulosten ryhmittely tietyn sarakkeen perusteella tapahtuu komennon GROUP BY perustella. Komento GROUP BY lisätään taulujen listauksen ja mahdollisten kyselyn rajausehtojen jälkeen. Komentoa GROUP BY seuraa sarake, jonka perusteella tulokset ryhmitellään. Jotta ryhmittelystä tulee mielekäs, asetetaan ryhmittelyn peruste tyypillisesti myös SELECT-komentoa seuraavaan sarakelistaukseen.
SELECT ryhmittelysarake, FUNKTIO(sarake) FROM Taulu
GROUP BY ryhmittelysarake
Alla muutamia esimerkkejä:
-
Kuinka monta matkaa kullakin lentoyhtiöllä on tarjolla?
SELECT yhtio, COUNT(*) FROM Lentomatka GROUP BY yhtio -
Kuinka monta alle 100 minuutin pituista lentomatkaa eri kaupungeista lähtee?
SELECT lahtopaikka, COUNT(*) FROM Lentomatka WHERE pituus < 100 GROUP BY lahtopaikka -
Kuinka pitkiä kunkin lentoyhtiön matkat ovat keskimäärin?
SELECT yhtio, AVG(pituus) FROM Lentomatka GROUP BY yhtio
Taulujen yhdistäminen toimii kuten ennen. Valittavat taulut kerrotaan joko FROM -avainsanan jälkeen tai JOIN -avainsanan jälkeen, riippuen tavasta, jolla yhdistäminen tehdään. Ryhmittelykomento tulee mahdollisten WHERE-ehtojen jälkeen.
Oletetaan seuraavat taulut Kurssi ja Kurssitehtävä.
- Kurssi((pk) id, nimi, opintopisteet)
- Kurssitehtava((pk) id, (fk) kurssi_id -> Kurssi, tehtava)
Kurssikohtaisten tehtävien lukumäärän laskeminen onnistuu seuraavasti. Avainsana AS muuntaa tuloksena saatavassa taulussa olevan sarakkeen nimen.
SELECT Kurssi.nimi AS kurssi, COUNT(*) AS tehtäviä FROM Kurssi, Kurssitehtävä
WHERE Kurssi.id = Kurssitehtava.kurssi_id
GROUP BY Kurssi.nimi
Edellä kuvatun kyselyn tuloksia tarkastellessa huomaamme, että tuloksissa ei ole yhtäkään tehtävätöntä kurssia. Tämä selittyy kyselyillämme -- olemme valinneet mukaan vain rivit, joilla hakuehdot täyttyvät. Kirjoitetaan edellinen kysely siten, että otamme huomioon kurssit vaikka niihin ei liittyisikään yhtäkään toisen taulun riviä -- käytämme siis LEFT JOIN-liitosoperaatiota.
SELECT Kurssi.nimi AS kurssi, COUNT(Kurssitehtava.id) AS tehtäviä FROM Kurssi
LEFT JOIN Kurssitehtävä ON Kurssi.id = Kurssitehtava.kurssi_id
GROUP BY Kurssi.nimi
Edellä COUNT-funktiolle annetaan parametrina kurssitehtävän id. Jos funktiolle annetaan parametrina *, myös NULL-arvo -- eli tyhjä arvo -- lasketaan (ainakin joissain tietokannanhallintajärjestelmissä).
Ryhmittely useamman sarakkeen perusteella
Komennolle GROUP BY voi antaa myös useampia sarakkeita, jolloin ryhmittely tapahtuu sarakeryhmittäin. Esimerkiksi ryhmittely GROUP BY kurssi, arvosana ryhmittelisi taulussa olevat rivit ensin kurssin perusteella, jonka jälkeen kurssikohtaiset ryhmät ryhmiteltäisiin vielä arvosanan perusteella. Tällöin jokaiselle kurssille tulisi erilliset arvosanaryhmät.
Oletetaan edellä kuvatun taulun lisäksi taulut Kurssisuoritus ja Opiskelija:
- Kurssisuoritus((pk) id, (fk) kurssi_id -> Kurssi, opiskelija_id -> Opiskelija, arvosana, paivamaara)
- Opiskelija((pk) id, opiskelijanumero, nimi, syntymävuosi)
Kurssikohtaiset arvosanaryhmät saa selville seuraavalla kyselyllä.
SELECT Kurssi.nimi AS kurssi, Kurssisuoritus.arvosana AS arvosana, COUNT (*) AS lukumäärä
FROM Kurssi, Kurssisuoritus
WHERE Kurssi.id = Kurssisuoritus.kurssi_id
GROUP BY Kurssi.nimi, Kurssisuoritus.arvosana
Tulosten järjestäminen
Kyselyn tulokset voi järjestää komennolla ORDER BY, jota seuraa järjestettävät sarakkeet. Sarakkeelle voi antaa myös lisämääreen ASC (ascending), joka kertoo että tulokset tulee järjestää nousevaan järjestykseen, ja DESC (descending), joka kertoo että tulokset tulee järjestää laskevaan järjestykseen. Oletuksena järjestys on nouseva.
Komento ORDER BY tulee kyselyn loppuun. Edellisen kurssiarvosanatilaston tulokset saisi kurssin nimen perusteella järjestykseen seuraavasti.
SELECT Kurssi.nimi AS kurssi, Kurssisuoritus.arvosana AS arvosana, COUNT (*) AS lukumäärä
FROM Kurssi, Kurssisuoritus
WHERE Kurssi.id = Kurssisuoritus.kurssi_id
GROUP BY Kurssi.nimi, Kurssisuoritus.arvosana
ORDER BY Kurssi.nimi
Hakutulosten rajaaminen yhteenvetokyselyissä
Yhteenvetokyselyissä laskettavat tulokset kuten summa, rivien lukumäärä ja keskiarvo muodostetaan vasta, kun kaikki kyselyn rivit on selvillä. Kyselyiden tuloksen rajaamiseen käytetty WHERE toimii siten, että se tarkastelee tuloksia riveittäin -- se ei osaa odottaa summan laskemisen lopputulosta.
Jos yhteenvetokyselyn tuloksen perusteella halutaan rajata tuloksia, tulee käyttää HAVING-ehtoa. HAVING ehto tarkastetaan vasta, kun yhteenvetokyselyn tulokset ovat selvillä. Ehto HAVING lisätään ryhmittelykyselyn jälkeen esimerkiksi seuraavalla tavalla.
SELECT Kurssi.nimi AS kurssi, AVG(Kurssisuoritus.arvosana) keskiarvo
FROM Kurssi, Kurssisuoritus
WHERE Kurssi.id = Kurssisuoritus.kurssi_id
GROUP BY Kurssi.nimi
HAVING keskiarvo < 2
ORDER BY Kurssi.nimi
Yllä olevalla kyselyllä saadaan selville ne kurssit, joihin liittyvien kurssisuoritusten keskiarvo on alle 2.
Kuten esimerkissä näkyy, samassa kyselyssä voi olla sekä WHERE-ehto että HAVING-ehto.
Jatketaan edellisestä tehtävästä tutun tietokannan parissa..
Tehtäväpohjan kansiossa db tulee tiedosto nimeltä Chinook_Sqlite.sqlite. Tietokannassa on seuraavat taulut:
sqlite> .tables Album Employee InvoiceLine PlaylistTrack Artist Genre MediaType Track Customer Invoice Playlist
Tietokanta kuvaa digitaalisen musiikin myyntipalvelua. Tietokannan relaatiokaavio löytyy osoitteesta https://github.com/lerocha/chinook-database/wiki/Chinook-Schema. Kirjoita SQLiten avulla kyselyt, joilla saa selville seuraavat tiedot.
- Kysely 1: Kuinka monta kappaletta kuhunkin genreen liittyy? Tuloksessa tulee olla kaksi saraketta, joista toisen nimi on
genreja toisen nimi onkappaleita. - Kysely 2: Kuinka monta kappaletta kustakin genrestä on ostettu? Voit olettaa, että kappale on ostettu jos lasku on olemassa. Tuloksessa tulee olla kaksi saraketta, joista toisen nimi on
genreja toisen nimi onostettuja. - Kysely 3: Kuinka monella levyllä kukin artisti esiintyy? Tuloksessa tulee olla kaksi saraketta, joista toisen nimi on
artistija toisen nimi onlevyt.
Kun olet saanut kyselyt toimimaan, kopioi ne tehtäväpohjassa olevan luokan Kyselyja metodeihin kysely1, kysely2 ja kysely3. Metodeihin tulee kopioida SQL-kieliset kyselyt, joilla em. kysymyksiin saa vastaukset, ei siis vastauksia.
Huom! Tehtävässä on tilanteita, missä yhteenvetokyselyn tuloksessa esiintyvä lukumäärä (esim. kappaleet, ostetut, levyt) voi olla 0.
Alikyselyt
Alikyselyt ovat nimensä mukaan kyselyn osana suoritettavia alikyselyitä, joiden tuloksia käytetään osana pääkyselyä. Pohditaan kysymystä Miten haen opiskelijat, jotka eivät ole vielä osallistuneet yhdellekään kurssille?, ja käytetään siihen ensin aiemmin tutuksi tullutta tapaa, eli LEFT JOIN -kyselyä. Yhdistetään opiskelijaa ja kurssisuoritusta kuvaavat taulut LEFT JOIN-kyselyllä siten, että myös opiskelijat, joilla ei ole suorituksia tulevat mukaan vastaukseen. Tämän jälkeen, jätetään vastaukseen vain ne rivit, joilla kurssisuoritukseen liittyvät tiedot ovat tyhjiä -- tämä onnistuu katsomalla mitä tahansa kurssisuoritus-taulun saraketta, ja tarkistamalla onko se tyhjä, eli null. Tämä onnistuu seuraavasti:
SELECT opiskelijanumero FROM Opiskelija
LEFT JOIN Kurssisuoritus
ON Opiskelija.id = Kurssisuoritus.opiskelija_id
WHERE Kurssisuoritus.kurssi_id IS null
Toinen vaihtoehto edellisen kyselyn toteuttamiseen on luoda kysely, joka hakee kaikki ne opiskelijat, jotka eivät ole kurssisuorituksia saaneiden opiskelijoiden joukossa. Tässä on oleellisesti kaksi kyselyä: (1) hae niiden opiskelijoiden tunnus, joilla on kurssisuoritus, ja (2) hae opiskelijat, jotka eivät ole edellisen kyselyn palauttamassa joukossa.
Ensimmäinen kysely on suoraviivainen.
SELECT opiskelija_id FROM Kurssisuoritus
Toinenkin kysely on melko suoraviivainen -- avainsanalla NOT IN voidaan rajata joukkoa.
SELECT * FROM Opiskelija
WHERE id NOT IN (ensimmainen kysely)
Yhdessä kyselyt ovat siis muotoa:
SELECT * FROM Opiskelija
WHERE id NOT IN (
SELECT opiskelija_id FROM Kurssisuoritus
)
Käytännössä alikyselyt tuottavat kyselyn tuloksena taulun, josta pääkyselyssä tehtävä kysely tehdään. Ylläolevassa esimerkissä alikyselyn tuottamassa taulussa on vain yksi sarake, jossa on kurssisuorituksen saaneiden opiskelijoiden opiskelijanumerot.
Määreen NOT IN, joka tarkastaa että valitut arvot eivät ole alikyselyn tuottamassa taulussa, lisäksi käytössä on määre IN. Määreen IN avulla voidaan luoda ehto, jolla tarkastetaan, että valitut arvot ovat annetussa joukossa tai taulussa. Esimerkiksi alla haetaan kaikki kurssisuoritukset, joissa arvosana on kolme tai viisi.
SELECT * FROM Kurssisuoritus WHERE arvosana IN (3, 5)
Määreiden IN ja NOT IN lisäksi alikyselyissä voidaan käyttää määreitä EXISTS ja NOT EXISTS, joiden avulla voidaan rajata hakujoukkoa alikyselyssä olevan ehdon perusteella. Voimme esimerkiksi kirjoittaa aiemmin kirjoitetun kursseja suorittamattomia opiskelijoita etsivän kyselyn siten, että jokaisen Opiskelija-taulussa olevan opiskelijanumeron kohdalla tarkistetaan, että sitä ei löydy taulusta Kurssisuoritus.
SELECT opiskelijanumero FROM Opiskelija
WHERE NOT EXISTS (
SELECT opiskelija_id FROM Kurssisuoritus
WHERE Kurssisuoritus.opiskelija_id = Opiskelija.id
)
Edellä oleva kysely tarkistaa jokaisen Opiskelija-taulussa olevan opiskelijanumeron kohdalla ettei sitä löydy Kurssisuoritus-taulun opiskelija-sarakkeesta. Käytännössä -- jos tietokantamoottori ei optimoi kyselyä -- jokainen opiskelija-taulun rivi aiheuttaa uuden kyselyn kurssisuoritus-tauluun, mikä tekee kyselystä tehottoman.
Jokainen SQL-kysely tuottaa tuloksena taulun. Taulussa voi olla tasan yksi sarake ja rivi, tai vaikkapa tuhansia rivejä ja kymmeniä sarakkeita. Silloinkin, kun suoritamme yksinkertaisen haun, kuten vaikkapa "Hae kaikki kurssilla 'Tietokantojen perusteet' olevat opiskelijat", on haun tuloksena taulu.
Kaikki tekemämme SQL-kyselyt ovat liittyneet tauluihin. Emmekö siis voisi tehdä kyselyjä myös vastauksiin? Vastaus on kyllä.
Esimerkiksi vanhimman (tai vanhimmat, jos tämä ei ole yksikäsitteistä) opiskelijan löytää -- muunmuassa -- etsimällä kaikista pienimmän mahdollisimman syntymävuoden (kyselyn tulos on taulu), jonka jälkeen vastaustaulussa olevaa tulosta verrataan kaikkien opiskelijoiden syntymävuosiin.
SELECT * FROM Opiskelija
WHERE syntymävuosi
IN (SELECT MIN(syntymavuosi) FROM Opiskelija)
Tietokantakyselyiden tehokkuudesta
Tietokantaan tehtävä SQL-kielinen kysely voidaan suorittaa useammalla eri tavalla. Kyselyn suoritus voi käydä läpi tietokantataulun jokaisen rivin, se voi tarkastella vain rajattua osaa tietokantataulun riveistä, tai suoritus voi olla useamman taulun tapauksessa jonkinlainen yhdistelmä edellisiä. Kyselystrategia perustuu tietokannanhallintajärjestelmän sisäisen kyselynoptimoijan sekä tietokantatauluihin määriteltyjen ominaisuuksien kuten indeksien perusteella.
Tietokantakyselyn tarkastelu
Tietokantakyselyiden suoritusstrategiaa voi tarkastella tietokannanhallintajärjestelmäkohtaisen apukyselyn avulla. SQLitessä kyselyn sisältöön pääsee kommennolla EXPLAIN QUERY PLAN, jota seuraa konkreettinen kysely. Suoritusstrategia sisältää tiedon läpikäytävistä tietokannoista sekä kyselyn muodosta. Kyselyn muoto on joko "SCAN" tai "SEARCH". Muoto SCAN käy koko tietokantataulun läpi ja SEARCH tarkastelee tietokantatauluun liittyvää indeksiä.
Tarkastellaan tätä konkreettisen esimerkin kautta. Oletetaan, että käytössämme on tietokanta, jossa on seuraavat tietokantataulut.
CREATE TABLE Asiakas (
id integer PRIMARY KEY,
nimi varchar(200),
puhelinnumero varchar(20),
katuosoite varchar(50),
postinumero integer,
postitoimipaikka varchar(20)
);
CREATE TABLE Tilaus (
id integer PRIMARY KEY,
asiakas_id integer,
aika date,
kuljetustapa varchar(40),
vastaanotettu boolean,
toimitettu boolean,
FOREIGN KEY (asiakas_id) REFERENCES Asiakas(id)
);
Jos haluamme listata asiakkaiden nimet ja puhelinnumerot, teemme kyselyn "SELECT nimi, puhelinnumero FROM Asiakas". Strategia on selvä -- käydään koko tietokantataulu läpi. Ensimmäisessä esimerkissä kytketään lisäksi SQLiten otsikot päälle ja vaihdetaan tulostusmuotoa kolumnimuotoon. Alla olevissa esimerkeissä on lisäksi käytetty .width -komentoa tulostuksen leveyden sovittamiseksi.
sqlite> .headers on sqlite> .mode column sqlite> EXPLAIN QUERY PLAN SELECT nimi, puhelinnumero FROM Asiakas; selectid order from detail -------- ----- ---- ------------------ 0 0 0 SCAN TABLE Asiakas
Vastaava strategia liittyy myös tietyn nimisen asiakkaan etsimiseen. Alla kuvatussa esimerkissä tarkastellaan kyselyä, missä etsitään Cobb-nimistä asiakasta.
sqlite> EXPLAIN QUERY PLAN SELECT nimi, puhelinnumero
FROM Asiakas WHERE nimi = 'Cobb';
selectid order from detail
-------- ----- ---- ------------------
0 0 0 SCAN TABLE Asiakas
Myös Tilaus-taulun tietojen listaaminen vaatii koko tietokantataulun läpikäynnin. Alla listataan tilaukset, jotka on jo toimitettu.
sqlite> EXPLAIN QUERY PLAN SELECT * FROM Tilaus
WHERE toimitettu = 1;
selectid order from detail
-------- ----- ---- -----------------
0 0 0 SCAN TABLE Tilaus
Tarkastellaan seuraavaksi hieman monimutkaisempaa kyselyä, missä tulostetaan niiden asiakkaiden nimet, jotka ovat tehneet vähintään yhden tilauksen.
sqlite> EXPLAIN QUERY PLAN SELECT nimi, puhelinnumero
FROM Asiakas JOIN Tilaus
ON Asiakas.id = Tilaus.asiakas_id;
selectid order from detail
-------- ----- ---- --------------------------------------------------------
0 0 1 SCAN TABLE Tilaus
0 1 0 SEARCH TABLE Asiakas USING INTEGER PRIMARY KEY (rowid=?)
Kysely onkin nyt erilainen. Kyselyssä käydään ensin läpi koko taulu Tilaus, jonka jälkeen etsitään tietokantataulusta Asiakas rivejä asiakas-taulun pääavaimen perusteella. Entä jos tietokantataulu Asiakas olisikin määritelty siten, että kenttä id ei olisi pääavain?
CREATE TABLE Asiakas (
id integer,
nimi varchar(200),
puhelinnumero varchar(20),
katuosoite varchar(50),
postinumero integer,
postitoimipaikka varchar(20)
);
sqlite> EXPLAIN QUERY PLAN SELECT nimi, puhelinnumero
FROM Asiakas JOIN Tilaus
ON Asiakas.id = Tilaus.asiakas_id;
selectid order from detail
-------- ----- ---- -----------------------------------------------------------------
0 0 0 SCAN TABLE Asiakas
0 1 1 SEARCH TABLE Tilaus USING AUTOMATIC COVERING INDEX (asiakas_id=?)
Tietokannanhallintajärjestelmä vaihtaa läpikäytävien taulujen järjestystyä. Nyt kysely käy ensin läpi koko Asiakas-taulun, ja etsii tämän jälkeen Tilaus-taulusta tietoa automaattisesti luodun indeksin perusteella.
Indeksit eli hakua nopeuttavat tietorakenteet
Indeksit ovat tietokantatauluista erillisiä yhden tai useamman sarakkeen tiedoista koostuvia tietorakenteita, jotka viittaavat tietokantataulun riveihin. Indeksirakenteita on useita erilaisia, mm. hajautustaulut ja puurakenteet. Indeksien tavoite on käytännössä -- tietokantojen yhteydessä -- tietokantakyselyiden nopeuttaminen.
Indeksiä voi ajatella perinteikkään kirjaston korttiluettelona. Kirjaston tiskille mentäessä ja tiettyä kirjaa kysyttäessä, kirjastovirkailija käy läpi kirjan nimen perusteella aakkostettuja kortteja. Koska nimet ovat aakkosjärjestyksessä, jokaista korttia ei tarvitse tarkastella tiettyä kirjaa etsittäessä. Kortissa on tieto kirjan konkreettisesta paikasta kirjastossa -- kun kortti löytyy, kirjan voi hakea. Jos kirjan nimen sijaan kirjaa etsitään kirjoittajan perusteella, tulee käyttää toista korttipakkaa, joka sisältää kirjoittajien nimet sekä mahdollisesti myös tiedon kirjojen nimistä. Jos kirjaa etsitään sisällön perusteella joudutaan huonolla tuurilla käymään jokainen fyysinen kirjaston kirja läpi.
Pohditaan tilannetta, missä miljardi riviä sisältävän taulun tiettyyn sarakkeeseen on määritelty indeksi. Oletetaan, että indeksi sisältää arvot järjestettynä. Tällöin, tiettyä arvoa haettaessa, voimme aloittaa keskimmäisestä arvosta -- jos haettava arvo on pienempi, tutkitaan "vasemmalla" olevaa puolikasta. Jos taas haettava arvo on suurempi, tutkitaan "oikealla" olevaa puolikasta. Alueen rajaaminen jatkuu niin pitkään, kunnes haettava arvo löytyy, tai rajaus päätyy tilanteeseen, missä tutkittavia arvoja ei enää ole. Tämä menetelmä -- puolitushaku tai binäärihaku lienee tuttu ohjelmointikursseilta.
Jos rivejä on yhteensä miljardi, voidaan ne jakaa kahteen osaan noin log2 1 000 000 000 kertaa, eli noin 30 kertaa. Jos oletamme, että arvoa ei löydy taulusta, tulee yhteensä tarkastella siis noin 30 riviä miljardin sijaan.
Indeksin määrittely tietokantataulun sarakkeelle tapahtuu tietokantataulun luomisen jälkeen komennolla CREATE INDEX, jota seuraa uuden indeksin nimi, avainsana ON, sekä taulu ja taulun sarakkeet, joille indeksi luodaan. Tietokannanhallintajärjestelmä luo tietokantataulun pääavaimelle ja viiteavaimille indeksit tyypillisesti automaattisesti.
Oletetaan, että sovelluksessamme asiakkaita haetaan usein nimen perusteella. Luodaan edellä kuvattuun Asiakas-taulun sarakkeelle nimi indeksi.
sqlite> CREATE INDEX idx_asiakas_nimi ON Asiakas (nimi);
Tarkastellaan aiemmin tehtyä Cobb-nimisen henkilön hakua uudelleen.
sqlite> EXPLAIN QUERY PLAN SELECT nimi, puhelinnumero FROM Asiakas
WHERE nimi = 'Cobb';
selectid order from detail
-------- ----- ---- ----------------------------------------------------------
0 0 0 SEARCH TABLE Asiakas USING INDEX idx_asiakas_nimi (nimi=?)
Strategia muuttuu edellisestä. Aiemmin tietokannanhallintajärjestelmän strategia on ollut koko tietokantataulun Asiakas läpikäynti, nyt tietoa haetaan indeksistä. Jos käytössä oleva indeksi olisi esimerkiksi hajautustaulu, tapahtuisi haku vakioajassa -- eli "tarkasteluja" tehtäisiin "yksi" riippumatta tietomäärästä -- tietorakenteisiin, niihin tehtäviin hakuihin sekä niiden tehokkuuksiin tutustutaan tarkemmin kurssilla tietorakenteet ja algoritmit.
Taulut ja sarakkeet, joihin indeksejä kannattaa harkita, liittyvät paljon suoritettuihin (ja hitaahkoihin) tietokantakyselyihin. Ensimmäiset askeleet liittyvät (1) tietokantataulujen pää- ja viiteavainten indeksien luomiseen, (2) hakuehtoihin liittyvien sarakkeiden indeksien luomiseen sekä (3) järjestysehtoihin liittyvien sarakkeiden indeksien lumiseen. Alla on kuvattuna eräs suoraviivainen prosessi tietokantataulun indeksien päättämiselle: lähtökohtana on kysely.
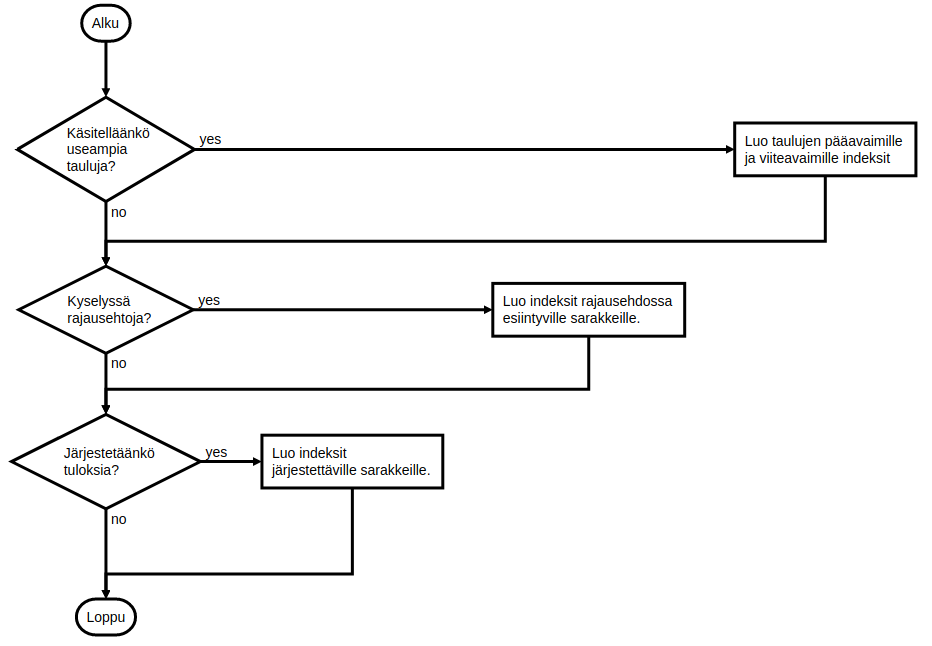
Indeksin luominen tietokantataululle luo tietorakenteen, jota käytetään tiedon hakemiseen. Jokaista indeksiä tulee päivittää myös tietokantaa muokkaavien operaatioiden yhteydessä, jotta indeksin tiedot ovat ajan tasalla. Käytännössä liiallinen indeksien luominen saattaa myös hidastaa sovelluksen toimintaa.
Välimuistit sovelluksissa
Kun tietokantaa käytetään osana annettua sovellusta (esimerkiksi web-sovellusta), sovelluksen vastuulla on tietokantakyselyiden tekeminen tietokannanhallintajärjestelmään. Jos sovellus on ainoa tietokannan käyttäjä (tietokantaa ei muokata muista järjestelmistä), ja jos merkittävä osa kyselyistä on toistuvia hakukyselyjä, voi sovellukseen rakentaa tietokannan toimintaa abstrahoiva välimuisti.
Välimuistissa on käytännössä kyse käsiteltävän tiedon tuomisesta lähemmäksi käyttäjää. Tietokantaa käyttävien sovellusten tapauksessa usein haettava tieto tuodaan sovelluksen muistiin, jolloin sovelluksen ei tarvitse hakea tietoa erikseen tietokannasta. Välimuisti tyhjennetään aina tietokannan päivityksen yhteydessä, jolloin käyttäjälle päätyvä tieto on aina ajan tasalla.
Yksinkertaisimmillaan välimuistitoteutus voi olla olemassaolevan Dao-toteutuksen kapselointi erilliseen Dao-toteutukseen. Oletetaan, että käytössämme on kolmannelta viikolta tuttu vaillinainen AsiakasDao-toteutus. Välimuistillisen toteutuksen luominen on melko suoraviivaista -- alla toteutuksessa muistetaan vain yksittäiset asiakkaat.
import java.util.*;
import java.sql.*;
public class CachedAsiakasDao extends AsiakasDao implements Dao<Asiakas, Integer> {
private HashMap<Integer, Asiakas> asiakkaatAvaimilla;
public CachedAsiakasDao(Database database) {
super(database);
this.asiakkaatAvaimilla = new HashMap<>();
}
@Override
public Asiakas findOne(Integer key) throws SQLException {
if (!asiakkaatAvaimilla.containsKey(key)) {
Asiakas asiakas = super.findOne(key);
asiakkaatAvaimilla.put(key, asiakas);
}
return asiakkaatAvaimilla.get(key);
}
@Override
public Asiakas saveOrUpdate(Asiakas object) throws SQLException {
Asiakas asiakas = super.saveOrUpdate(object);
asiakkaatAvaimilla.put(asiakas.getId(), asiakas);
return asiakas;
}
@Override
public void delete(Integer key) throws SQLException {
this.asiakkaatAvaimilla.removeKey(key);
return super.delete(key);
}
}
Jos asiakkaiden tietohin liittyvistä tietokantakyselyistä 99% on hakuoperaatioita, on merkittävässä osassa tapauksia tieto valmiiksi sovelluksen käytössä, jolloin tietokantaan ei tarvitse ottaa yhteyttä. Toisaalta, jos sovellus on sellainen, että merkittävä osa käsittelystä sisältää myös tietokannassa olevan tiedon muokkausoperaatioita, ei edellä kuvatusta välimuistista ole juurikaan hyötyä.
Tietokannan eheys ja transaktiot
Eheydellä viitataan tallennetun tiedon oikeellisuuteen. Tietokannanhallintajärjestelmä ylläpitää tietokannan eheyttä jatkuvasti. Esimerkiksi sarakkeen, joka on määritelty sisältämään vain numeerista tietoa, ei pitäisi sisältää tekstimuotoista tietoa. Vastaavasti viiteavainten tulee viitata aina olemassaolevaan tietoon.
Eheyden ylläpitämisen sekä kohta tutuksi tulevien tietokantatransaktioiden ymmärtämiseksi on hyvä tuntea tietokannan toimintaa sovellustasolla. Kurssin ensimmäisessä osassa tarkasteltiin tiedon käsittelyä tiedostoissa -- tietokanta käyttää kiintolevyä tiedon tallentamiseen, mutta rivien käsittely tapahtuu (keskus)muistissa. Kun riviä halutaan päivittää, se haetaan ensin kovalevyltä muistiin, päivitetään ja viedään takaisin levylle.
Keskusmuistin ongelma on se, että sen sisältö häviää esimerkiksi sähkökatkoksen sattuessa tai palvelimen kaatuessa. Havainnollistetaan ongelmallisuutta esimerkeillä:
- Annetaan kaikille yrityksen 1000000 kuukausipalkkaiselle työntekijälle 5% palkan korotus.
UPDATE Palkat SET kkpalkka = kkpalkka * 1,05Mitä jos tietokantapalvelin kaatuu, kun vasta 10000 muutettua riviä on tallennettu levylle? 990000 vihaista työntekijää jää ilman palkankorotusta? Tarvitaan jokin keino varmistaa, että päivitys tehdään kokonaan tai ei lainkaan. - Entä jos palkkojen maksuun liittyvä prosessi lukee palkkatietoja juuri samalla kun niitä ollaan päivittämässä? Lukuoperaatio voi lukea esimerkiksi vain tietyn toimipaikan työntekijöiden palkat - 100 riviä. Jos päivitys on yhtäaikaa kesken, voi käydä niin, että osaan luetuista riveistä on ehditty jo tehdä päivitys ja osaan ei. Nyt osa työntekijöistä saa syyskuun palkkansa korotettuna ja osa ei? Tarvitaan jokin keino hallita yhtäaikaisia prosesseja.
Tietokantatransaktiot
Tietokantatransaktiot ratkaisevat edellä mainitut ongelmat. Ongelmat voidaan jakaa kahteen kategoriaan:
- Operaatioden keskeytymiset järjestelmän kaatuessa, häiriötilanteissa tai hallituissa keskeytyksissä
- Samanaikaset prosessit
Tietokantatransaktio sisältää yhden tai useamman tietokantaan kohdistuvan operaation, jotka suoritetaan (järjestyksessä) kokonaisuutena. Jos yksikin operaatio epäonnistuu, kaikki operaatiot perutaan, ja tietokanta palautetaan tilaan, missä se oli ennen transaktion aloitusta. Klassinen esimerkki tietokantatransaktiosta on tilisiirto, missä nostetaan rahaa yhdeltä tililtä, ja siirretään rahaa toiselle tilille. Jos tilisiirron suoritus ei onnistu -- esimerkiksi rahan lisääminen toiselle tilille epäonnistuu -- tulee myös rahan nostaminen toiselta tililtä perua.
Jokainen tietokantakysely suoritetaan omassa transaktiossaan, mutta, käyttäjä voi myös määritellä useamman kyselyn saman transaktion sisälle. Transaktio aloitetaan komennolla BEGIN TRANSACTION, jota seuraa kyselyt, ja lopulta komento COMMIT. Oletetaan, että käytössämme on taulu Tili(id, saldo).
CREATE TABLE Tili (
id integer PRIMARY KEY,
saldo NOT NULL
);
Tilisiirto kahden tilin välillä toteutetaan yhtenä transaktiona seuraavasti.
BEGIN TRANSACTION;
UPDATE Tili SET saldo = saldo - 10 WHERE id = 1;
UPDATE Tili SET saldo = saldo + 10 WHERE id = 2;
COMMIT;
Ylläolevassa transaktiossa suoritetaan kaksi kyselyä, mutta tietokannan näkökulmasta toiminto on atominen, eli sitä ei voi pilkkoa osiin. Komennon COMMIT yhteydessä muutokset joko tallennetaan kokonaisuudessaan tietokantaan, tai tietokantaan ei tehdä minkäänlaisia muutoksia.
Tietokantatransaktiota kirjoittaessa, ohjelmoija voi huomata tehneensä virheen. Tällöin suoritetaan komento ROLLBACK, joka peruu aloitetun transaktion aikana tehdyt muutokset. Suoritettua (COMMIT) tietokantatransaktiota ei voi perua.
Alla esimerkki kahdesta tietokantatransaktiosta. Ensimmäinen perutaan, sillä siinä yritettiin vahingossa siirtää rahaa väärälle tilille. Toinen suoritetaan. Kokonaisuudessaan allaolevan kyselyn lopputulos on se, että tililtä 1 on otettu 10 rahayksikköä, ja tilille 2 on lisätty 10 rahayksikköä.
BEGIN TRANSACTION;
UPDATE Tili SET saldo = saldo - 10 WHERE id = 1;
UPDATE Tili SET saldo = saldo + 10 WHERE id = 3;
ROLLBACK;
BEGIN TRANSACTION;
UPDATE Tili SET saldo = saldo - 10 WHERE id = 1;
UPDATE Tili SET saldo = saldo + 10 WHERE id = 2;
COMMIT;
Jokainen tietokantakysely -- myös "yhden rivin kyselyt" -- suoritetaan transaktion sisällä. Tietokannanhallintajärjestelmän vastuulla on vahtia, että transaktiot suoritetaan peräkkäin siten, että samaa tietoa ei voida käsitellä useammasta transaktiosta saman aikaan.
Tietokantatransaktiot ja rajoitteet
Koska tietokannanhallintajärjestelmä näkee transaktioiden sisällä suoritettavat käskyt atomisina, eli yksittäisenä kokonaisuutena, voivat tietokantatauluun määritellyt rajoitteet olla hetkellisesti rikki, kunhan ne transaktion suorituksen jälkeen ovat kunnossa.
Esimerkiksi suomen kirjanpitosääntöjen mukaan jokaisessa yrityksessä tulee olla kaksinkertainen kirjanpito. Tässä jokaisen tilitapahtuman yhteydessä tulee merkitä sekä mistä raha on otettu (debit), että mihin raha on laitettu (credit). Tällaisessa järjestelmässä tulee olla (esimerkiksi) tietokantataulu Kirjanpitotapahtuma, johon muutokset merkitään.
CREATE TABLE Kirjanpitotapahtuma
(
id integer PRIMARY KEY,
paivamaara date NOT NULL,
kirjanpitotili integer NOT NULL,
kuvaus text NOT NULL,
debit integer NOT NULL,
credit integer NOT NULL,
FOREIGN KEY(kirjanpitotili) REFERENCES Tili(id),
CONSTRAINT kirjaus_tasmaa CHECK (SUM(debit) = SUM(credit))
)
Nyt yhden transaktion sisällä voi tehdä useamman kirjanpitotapahtuman, kunhan transaktion suorituksen yhteydessä kirjanpitotapahtumien debit- ja credit-sarakkeiden summa täsmää. Yllä tietokantataulun luomiskomentoon on lisätty rajoite (CONSTRAINT), jonka avulla tietokantatauluun voidaan lisätä sääntöjä, joiden tulee olla aina transaktion jälkeen voimassa.
Netti on täynnä hyviä oppaita. Osoitteessa http://www.sqlitetutorial.net/sqlite-java/transaction/ on eräs tällainen. Tutustu oppaaseen.
Luo tehtäväpohjaan oppaan kuvaama tiedosto test.db sekä ohjelma, jossa lisäät tietokantaan useamman rivin saman transaktion sisällä.
Tässä tehtävässä ei ole testejä. Palauta tehtävä se toimii toivotulla tavalla.
Tietokannanhallintajärjestelmän ominaisuuksia
ACID (Atomicity, Consistency, Isolation, Durability) on joukko tietokannanhallintajärjestelmän ominaisuuksia:
- Atomisuudella (
Atomicity) varmistetaan, että tietokantatransaktio suoritetaan joko kokonaisuudessaan tai ei lainkaan. Jos tietokannanhallintajärjestelmään tehtävät transaktiot eivät olisi atomisia, voisi esimerkiksi päivityskyselyistä päätyä tietokantaan asti vain osa -- tilisiirtoesimerkissä vain rahan ottaminen yhdeltä tililtä, mutta ei sen lisäämistä toiselle. - Eheydellä (
Consistency) varmistetaan, että tietokantaan määritellyt rajoitteet, kuten viiteavaimet, pätevät jokaisen transaktion jälkeen. Jos tietokanta ei mahdollistaisi eheystarkistusta, voisi esimerkiksi kirjanpito olla virheellinen. - Eristyvyydellä (
Isolation) varmistetaan, että transaktio (A) ei voi lukea toisen transaktion (B) muokkaamaa tietoa ennenkuin toinen transaktio (B) on suoritettu loppuun. Tällä varmistetaan se, että jos transaktioita suoritetaan rinnakkaisesti, kumpikin näkee tietokannan eheässä tilassa. - Pysyvyydellä (
Durability) varmistetaan, että transaktion suorituksessa tapahtuvat muutokset ovat pysyviä. Kun käyttäjä lisää tietoa tietokantaan, tietokannanhallintajärjestelmän tulee varmistaa että tieto säilyy myös virhetilanteissa (jos transaktion suoritus onnistuu).
Perinteiset tietokannanhallintajärjestelmät tarvitsevat atomisuuden ja pysyvyyden toteuttamiseen write-ahead-lokia (WAL). Se tarkoittaa sitä, että suoritettavaksi tuleva tietokantaoperaatio tallennetaan tekstimuotoisena lokina levylle ennen rivien varsinaista päivitystä. Tällöin operaatiot voidaan suorittaa uudelleen, jos tietokantapalvelin kaatuu ennen kuin muistissa päivitetyt rivit ehditään tallentaa levylle. Tämä nopeuttaa tietokannan toimintaa merkittävästi, sillä pitkien operaatioiden kirjoittamista levylle ei tarvitse odottaa ennen kuin sovellukselle voidaan vastata operaation onnistuneen. Eristyvyyden toteuttamiseen käytetään mm. erilaisia taulu- ja rivilukitusmekanismeja. Kurssilla Transaktioiden hallinta tutustutaan tarkemmin transaktioiden toimintaan.
CAP-teoreema
Merkittävä osa sovellusten toiminnallisuuden skaalaamisesta suuremmille käyttäjäjoukoille perustuu sovellusten toiminnallisuuden kopiointiin useammalle tietokoneelle eli palvelimelle. Kun sovellusta pyörittävä palvelin ei pysty enää vastaamaan kaikkiin sille tehtyihin pyyntöihin, hankitaan uusi palvelin, johon sovellus kopioidaan. Osa pyynnöistä ohjataan jatkossa tälle palvelimelle, jolloin palvelimet pystyvät yhdessä käsittelemään pyynnöt.
Sovelluksen kopiointi useammalle palvelimelle aiheuttaa haasteita tiedon hallintaan ja oikeellisuuteen liittyen. Jos sovelluksen toteuttaja haluaa, että jokaisella sovelluksella oleva tieto on aina ajankohtaista ja että pyyntöön annettava vastaus on aina ajankohtainen palvelimesta riippumatta, tulee palvelinten kommunikoida ja päivittää tietoa keskenään. Pankit eivät esimerkiksi voi hyväksyä tilannetta, missä yhdellä palvelimella tilillä olisi rahaa ja yhdellä ei.
Tarkastellaan seuraavaksi lyhyesti CAP-teoreemaa. Sana CAP tulee termeistä Consistency, Availability, ja Partition tolerance.
- Consistency. Consistency viittaa järjestelmän ymmärrettävyyteen lineaarisesti toimivana prosessina. Mikäli järjestelmä toimii lineaarisesti (tai "Consistency" on olemassa), järjestelmän tulee aina palauttaa uusin mahdollinen tieto. Käytännössä jos järjestelmässä oleva prosessi B käynnistyy sen jälkeen kun prosessi A on suoritettu loppuun, ei prosessin B pitäisi koskaan nähdä tilaa, missä järjestelmä on ollut ennen prosessin A loppuun suorittamista. Huom! CAP-teoreeman Consistency ei ole sama kuin ACID-termin Consistency (eristäytyneisyys).
- Availability. Availability viittaa järjestelmän saatavuuteen. Jos järjestelmä on saatava (tai "Availability" on olemassa), jokaisen palvelimelle ohjautuvan pyynnön tulee palauttaa toivottu vastaus järkevän ajan puitteissa. Järjestelmässä ei siis saa olla tilannetta, missä palvelin on vastaamatta, vaikka sillä olisi siihen mahdollisuus.
- Partition tolerance. Partition tolerance viittaa siihen, että järjestelmän tulee toimia vaikka esimerkiksi palvelinkoneiden välinen yhteys olisi poissa käytöstä.
CAP on Eric Brewerin ehdottama teoreema, jonka mukaan (useammalle tietokoneelle) hajautettu ohjelmisto voi saavuttaa samaan aikaan vain kaksi yllä olevasta kolmesta ominaisuudesta.
Todellisuudessa tilanne on kuitenkin se, että palvelut toimivat verkossa, joka ei ole koskaan täysin luotettava. Tämä tarkoittaa sitä, että skaalautuvaa järjestelmää suunnitteleva joutuu käytännössä tekemään kompromissin Consistencyn ja Availabilityn välillä.
Jos järjestelmä vaatii lineaarisen toiminnan (kuten esimerkiksi pankki), mutta järjestelmän toiminta tulee hajauttaa useammalle koneelle, tulee järjestelmän olla vastaamatta pyyntöihin virhetilanteissa -- järjestelmä ei voi olla aina saatavilla. Vastaavasti, jos järjestelmän tulee olla aina saatavilla (esimerkiksi sosiaalisen median palvelu) ja järjestelmän toiminta tulee hajauttaa useammalle koneelle, tulee järjestelmälle antaa mahdollisuus lähettää palvelun käyttäjille myös vanhentunutta tietoa.
Tutustu myös Wikipedian artikkeliin Eventual consistency, mikä käsittelyy myös termiä BASE.
GDPR-lainsäädäntö
Viimeistään toukokuussa 2018 kaikki Euroopan Unionissa toimivat organisaatiot joutuvat noudattamaan uutta GDPR-lakia, joka ohjeistaa henkilökohtaisten tietojen käsittelyyn liittyvää toimintaa. Alla säädöksen ydinkohdat:
- Henkilötietojen keräämiseen tulee kysyä lupa. Jotta henkilökohtaisia tietoja saa kerätä, henkilön tulee eksplisiittisesti ja tietoisesti sallia tietojen kerääminen. Suostumuksen tietojen keruun sallimiseen tulee olla aito, eli tietojen keruusta pitää pystyä kieltäytymään ilman negatiivisia seuraamuksia.
- Mitä tahansa ei saa kerätä. Kerättävien tietojen tulee olla perusteltavissa ja kerättävien tietojen tulee olla rajattu vain niihin, mitä organisaatio tarvitsee toimintaansa.
- Henkilötietojen poistaminen pitää olla mahdollista. Henkilön tulee pystyä pyytämään tietojen poistamista järjestelmästä, ja tiedot tulee poistaa jos organisaatiolla ei ole mitään laillista syytä tiedon säilyttämiseen. Organisaation tulee myös informoida kolmannen osapuolen organisaatioita, joille henkilökohtaisia tietoja on annettu.
- Tietoa ei saa "vuotaa". Lainsäädäntö mahdollistaa sakkojen antamisen kerätyn tiedon huonosta käsittelystä. Organisaatio voi saada jopa sakot, jonka koko on 4% organisaation vuotuisesta liikevaihdosta.
- Ei vain Euroopan Unionissa. Myös Euroopan Unionin ulkopuoliset organisaatiot, joiden kohdeyleisönä on Euroopan Unionin jäsenet, ovat lain piirissä.
Tietojen käsittelyyn liittyviin oikeuksiin vaikuttaa myös käsittelijän tehtävä. Esimerkiksi Suomen koulutusjärjestelmällä on laillinen vastuu koulutuksen järjestämisestä -- omien koulutustietojen poistaminen ei todennäköisesti onnistu yliopiston rekisteristä, eikä yliopiston erikseen tule pyytää lupaa koulutustietojen tallentamiseen. Vastaavia poikkeuksia löytyy myös esimerkiksi tutkimukseen liittyen -- katso Anna Hännisen (OTM) video tietosuoja-asetuksesta sekä tieteellisestä tutkimuksesta.